
SubQuery is a fast & flexible blockchain indexing toolkit that powers thousands of developers over a hundred different blockchain networks. SubQuery APIs make your dApp lightning quick - by providing an indexed data layer, your dApps get richer data faster to allow you to build intuitive and immersive experiences for your users.
Our goal is to be the fastest and easiest indexer to use, to help power web3's transition to an open, efficient and user-centric future. Our new SDK4.0 release is a step forward on this journey with some incredible performance improvements.
What's New
SDK4.0 is all about speed, in this version our indexing performance takes a huge leap forward. Indexing performance is incredibly important with SubQuery, and when you’re indexing millions of blocks, it adds up to really make a difference. With faster sync times, developers can iterate faster and deliver features to market quicker.
SDK4.0 achieves this by optimising our multi-threading and optimisation of the store to reduce costly database writes. The most significant change however is the implementation of our new SubQuery Data Node and the new filtering RPC API. This API allows for much faster and efficient indexing by allowing the SDK to fetch much more targeted data. Instead of fetching all blocks or even whole blocks from an RPC, the SDK will only fetch relevant transactions and logs.
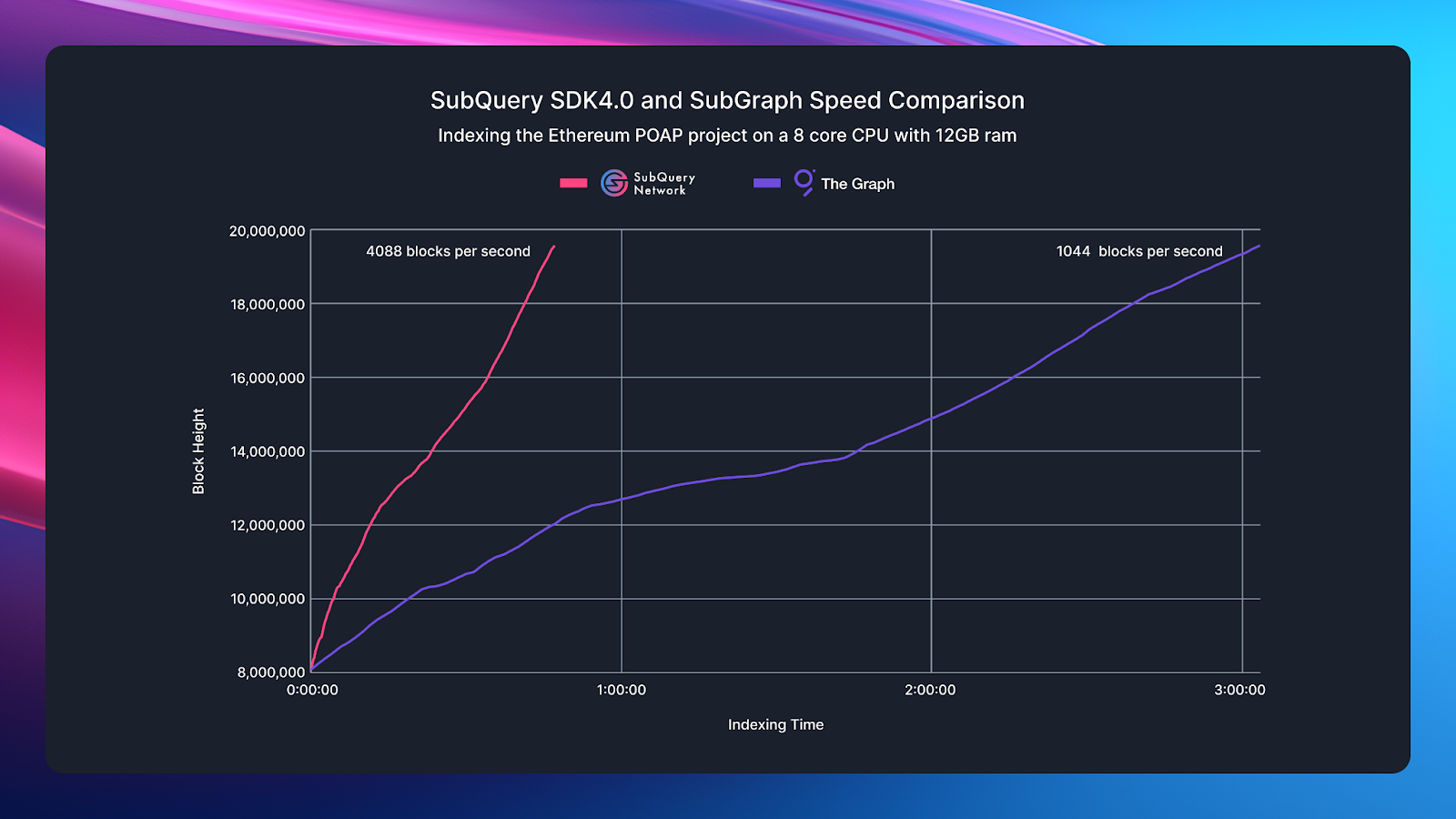
These changes mean that the SDK has a lot less data to process as well as reducing the amount of data the SDK needs to fetch from the network. As a result, when testing one of the most popular Subgraphs against SubQuery (Ethereum POAP indexing), SubQuery indexes almost 3.9x faster than the equivalent Subgraph.

Currently, the Ethereum SDK is supported with the new Data Nodes and the networks are limited to Ethereum and OP stack based networks but this will be expanded to other networks and network families in the future as well as prepares SubQuery to be able to source data from other types of blockchain data providers.
There are also some other improvements and changes in SDK4.0:
- Improved store functionality within mapping handlers, including the ability to specify an order to results from the getBy methods. Read the docs here.
- Support for multiple dictionary endpoints
Introducing the SubQuery Data Node
RPC services are the main interface to the blockchain, under the hood of your favourite dApp, dozens of requests are passing through RPC providers to query and submit transactions to the network.
However, the performance of SubQuery has long been limited by the RPC endpoint. RPCs are extremely costly and they’re not at all optimised for querying. This is compounded by the rise of L2 chains where, with higher throughput, the query performance and cost are major outstanding issues to address.
As promised, and earlier than expected, we have delivered the SubQuery Data Node, an enhanced and heavily-forked RPC node that is perfectly optimised for querying, especially on endpoints like eth_getLog, and the ability to filter transactions in a single API call.
The Data Node is open source, allowing people to contribute, extend, or fork the implementation in any way. SubQuery currently provides these Data Nodes:
- data-node-go-ethereum (forked from ethereum/go-ethereum for Ethereum and testnets). Public (beta) node https://ethereum.node.subquery.network/public
- data-node-op-geth (forked from ethereum-optimism/op-geth for Optimism, Base, and testnets). Public (beta) node coming soon
For example, you can query these standard Eth RPCs as well as additional data node RPCs:
curl -H 'content-type:application/json' -d '{"id": 1, "jsonrpc": "2.0", "method": "eth_blockNumber"}' 'https://ethereum.node.subquery.network/public'
Working together, the SubQuery Indexer and SubQuery Data Node provide the most performant indexing performance possible and in a completely decentralised way thanks to the SubQuery Network.
Our node runners will soon be able to run these data nodes on the network, bringing powerful and cost-effective RPC access to all, cementing SubQuery’s position as the fastest decentralised data indexer in web3.
Read more about the Data Node, including how to run one yourself, here.

What's Next
Later, SubQuery will work to democratise RPCs (and solve EIP-4444) in the process by delivering the Sharded Data Node, which will make RPCs cheaper to run and operate by node providers. EIP-4444 focuses on the sheer size of the node - an Ethereum archive requires about ~12 TB on Geth. SubQuery believes that in order to drive decentralisation of RPCs, you need to be able to make running these nodes easier and more accessible to everyday users.
SubQuery will extend its Data Node to support sharding, that is making each Data Node smaller by splitting up block ranges between node operators. Since SubQuery's Data Node only runs within the boundaries of a specific block range, it does not need to constantly sync new data, allowing it to optimise further for query performance rather than validation and verification.
About SubQuery
SubQuery Network is innovating web3 infrastructure with tools that empower builders to decentralise the future. Our fast, flexible, and open data indexer supercharges dApps on over 160 networks, enabling a user-focused web3 world. Soon, our Data Node will provide breakthroughs in the RPC industry, and deliver decentralisation without compromise. We pioneer the web3 revolution for visionaries and forward-thinkers. We’re not just a company — we’re a movement driving an inclusive and decentralised web3 era. Let’s shape the future of web3, together.
Linktree | Website | Discord | Telegram | Twitter | Blog | Medium | LinkedIn | YouTube





