

We are thrilled to announce the latest release of SubQuery SDK - v2.0. This is our biggest release yet and brings a number of changes to the leading Web3 data indexer, featuring significant performance improvements and powerful new features. With a commitment to providing the best possible experience for developers and users, we've focused on addressing key pain points and optimising efficiency in ways that all of our customers across 9 different chains will benefit from.
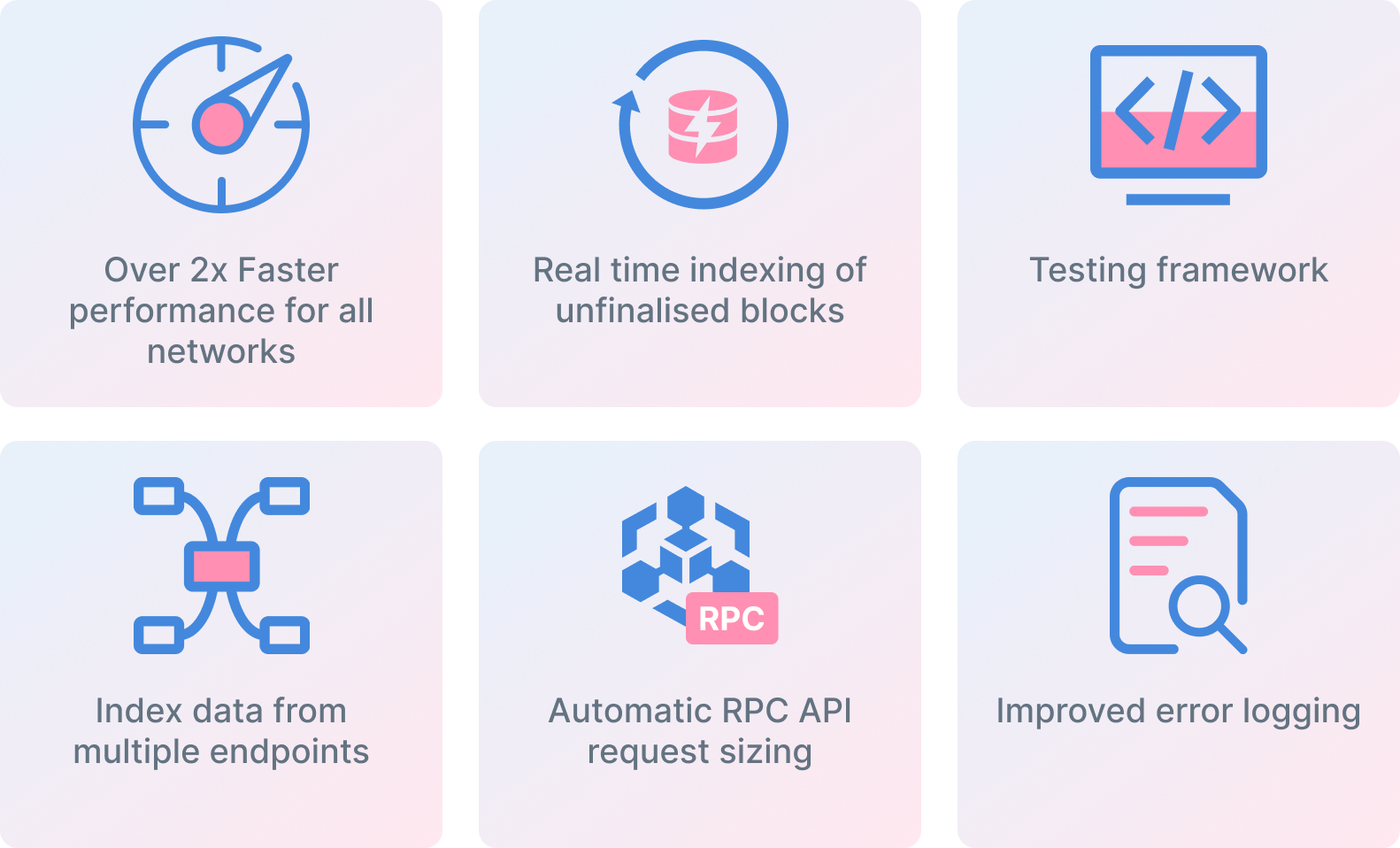
Here's an overview of the exciting updates in SubQuery 2.0:
2x Faster Performance across All Networks
SubQuery’s latest SDK brings major performance improvements to almost double the indexing speed across all supported networks (Polkadot, Ethereum, Polygon, BNB Smart Chain, Cosmos, Avalanche, NEAR, Algorand, and Flare), ensuring faster and smoother data indexing. Thanks to the implementation of a new advanced database cache, even data-heavy SubQuery projects will experience an impressive speed boost. By keeping more data in fast and efficient memory and saving it to the database in bulk operations, we've managed to enhance performance significantly.

Real-Time Indexing of Unfinalized Blocks
Since indexers are an additional layer within your tech stack, one of the biggest challenges is the time between when an on-chain event occurs, and when the data is processed and able to be queried from the indexer. Centralised providers like Subsquid are slower at this, since the data needs to be pre-indexed in an archive first, before it is again indexed by your own project, and then before it can be queried by your dApp. Each of these steps mean that users have to wait seconds between doing something on a blockchain and it showing up in their UI - which could have a significant effect on your dApp’s performance!
SubQuery provides real time indexing of unfinalised or unconfirmed data directly from the RPC endpoint that solves this problem. SubQuery takes the most probabilistic data before it is finalised/confirmed to provide to the app. In the unlikely event that the data isn’t finalised, SubQuery will automatically roll back and correct its mistakes quickly and efficiently - resulting in an insanely quick user experience for your customers.
Read the docs for Ethereum, Polygon, BNB Smart Chain, Flare, and Polkadot
Testing Framework
SubQuery 2.0 introduces a new testing framework that simplifies the process of testing mapping handlers and validating indexed data in an automated manner. This feature ensures data processing logic works as intended and helps detect errors early in the development process. Detailed summaries of failed tests enable developers to promptly identify and resolve issues, enhancing the quality and reliability of their SubQuery projects.
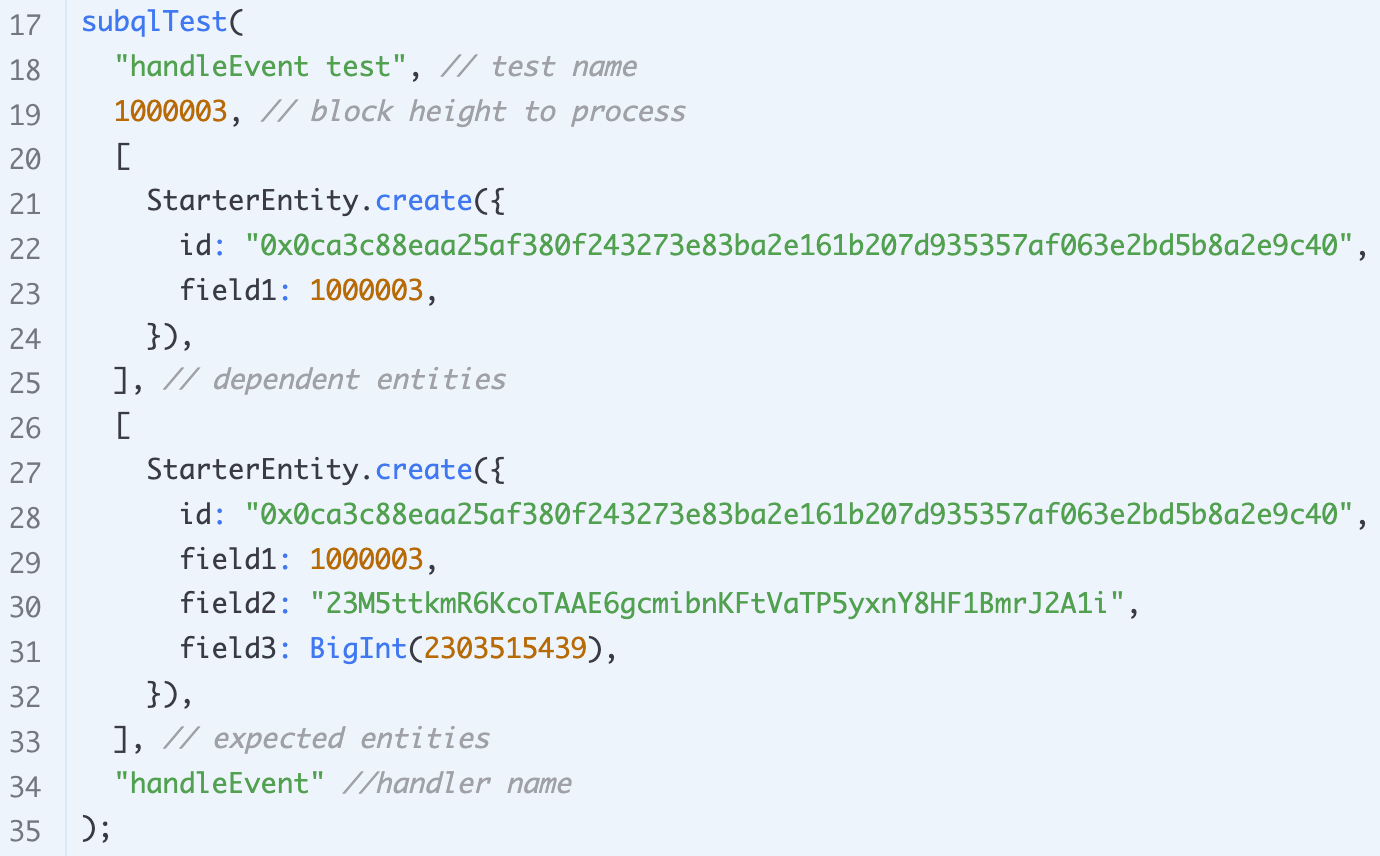
The testing framework has been added to all starter projects and is extremely easy to set up and use for all new projects. Additionally, we’ve provided examples on how developers can integrate it into their GitHub action pipelines to catch errors in commits to their source control, and also run it in Docker.
Index Data from Multiple RPC Endpoints
To increase speed, reliability, and reduce load on RPC providers, SubQuery 2.0 now supports indexing data from multiple RPC endpoints. This enhancement will provide the following benefits to your project:
- Increased speed - When enabled with worker threads, RPC calls are distributed and parallelised among RPC providers. Historically, RPC latency is often the limiting factor with SubQuery.
- Increased reliability - If an endpoint goes offline, SubQuery will automatically switch to other RPC providers to continue indexing without interruption.
- Reduced load on RPC providers - Indexing is a computationally expensive process on RPC providers, by distributing requests among RPC providers you are lowering the chance that your project will be rate limited.
Read more about this in the docs now
Automatic RPC API Request Sizing
SubQuery 2.0 intelligently and automatically optimises the size of requests to RPC endpoints, reducing the risk of being rate-limited. This improvement addresses the issue of rate-limited indexers, which previously caused significant errors.
Improved Error Logging
Lastly, we've made substantial improvements to error logging in SubQuery 2.0. Instead of providing only basic error information during runtime errors, we now offer much more detailed insights. This enhancement streamlines error diagnosis and accelerates the resolution process for your production projects, ultimately speeding up development time.
—
We are confident that the 2.0 version of the SubQuery SDK will elevate your Web3 data indexing experience to new heights. We look forward to your feedback and to continuing our journey together in making the Web3 ecosystem more accessible and efficient for all!
If you have any questions, please reach out to Sean Au or James Bayly or contact our Discord Technical Support
About SubQuery
SubQuery is a blockchain developer toolkit facilitating the construction of Web3 applications of the future. A SubQuery project is a complete API to organise and query data from Layer-1 chains. Currently servicing BNB, Ethereum, Polygon, NEAR, Polkadot, Avalanche, Algorand, Cosmos and Flare projects, this data-as-a-service allows developers to focus on their core use case and front-end without wasting time building a custom backend for data processing activities. In the future, the SubQuery Network intends to replicate this scalable and reliable solution in a completely decentralised manner.
Linktree | Website | Discord | Telegram | Twitter | Matrix | LinkedIn | YouTube