

One of the key components of Web3 infrastructure is the indexer. In simple terms, an indexer is a software component that indexes and organises data stored on the blockchain network into a more performant and available storage, allowing developers to query that data quickly and efficiently. Indexers are an essential part of Web3 infrastructure because they enable decentralised applications (dApps) to function fast and support the load of millions of users. You can read more here about the role of the indexer in your next dApp project, but in this article we’re going to dive into the things you should consider when selecting your indexer.
(De)centralisation
One of the biggest decisions that you need to make regarding the indexer of choice is centralisation or decentralisation. Decentralisation is an essential aspect of any blockchain-based decentralised applications (dApp), and since indexers make up a part of that, you will also need to consider the decentralisation of this important component of your technical stack.
- Performance: The vast majority of the time between doing something in a dApp and getting a response is the latency, or the time it takes for the data to move between the indexer’s server and the application. Decentralised indexers are generally more performant since they are distributed globally, meaning that there is less distance between your user and their data, and that you can spread the load more evenly across different indexers
- Reliability: Everyone that has ever run a production server knows that servers go down and issues happen at some point. With a centralised indexer, if that single server goes down, it could mean that your dApp will cease to work for hours or even days. Decentralised indexers are available 24/7 because they are not reliant on a single server.
- Improved Security and data sovereignty: Decentralised dApp indexers are more secure because they are distributed across multiple nodes, this makes it more difficult for an attacker to compromise the service with a DDOS attack. Additionally, decentralised dApp indexers are not controlled by a single entity or group and you can verify the accuracy of the data in the indexer and ensure that there is no manipulation or bias.
There is one downside to decentralised indexers though, and that is the initial indexing performance. Indexing is a computationally expensive project, analysing terabytes of data from tens of millions of blocks takes a long time, and with centralised indexers you can ensure that much higher levels of compute are used for this initial task in order to speed it up. However, this only applies to the initial sync, once your project is indexed, a centralised indexer provides no indexing performance benefits over a decentralised one!
In summary, just as decentralisation is critical for your dApp, it is also a critical aspect for your choice of indexer. A decentralised indexer can help to ensure that the data is accurate, unbiased, and accessible to everyone, and your dApp is performant and reliable.
SubQuery has always designed our multi-chain indexer with a strong belief in the principles of decentralisation. We are launching our decentralised network imminently, and it will bring all of these advantages to projects that currently rely on SubQuery.
Comparing Decentralised Indexers
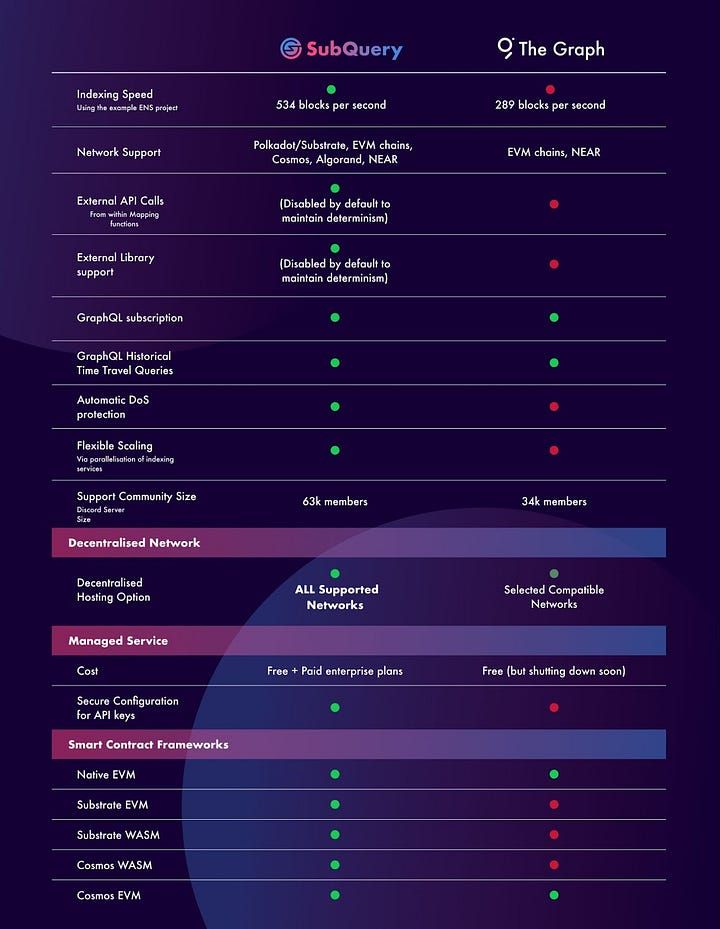
For developers who require or choose a decentralised indexing offering, the market leaders are The Graph and SubQuery. The Graph was established in July 2017 and is one of the most recognised projects in the Ethereum ecosystem while SubQuery launched in January 2020 with its origins in Polkadot. While there are numerous similarities, it is important to articulate some of the key differences between the two.
Let's consider each project under the following four key areas; openness, flexibility, speed, and universal support.
Openness
Both SubQuery and The Graph are open-source and welcome contributions from third party developers as well as their own community members. The documentation for both is understandable and easy to follow, and they both have democratic foundation with a shared goal of transitioning to a DAO.
Where SubQuery and the Graph differ is the openness of their decentralised network. The Graph’s decentralised network has been active since December 2020, but one of the key requirements to participate as an indexer in The Graph is a minimum stake amount of 100,000 GRT. This is a huge sum of tokens (over US$220,000 at its peak value in February 2021) that indexers must acquire just to stake the minimum to participate and has resulted in only a small number of large whales participating. Although SubQuery is yet to launch its network, one of its stated goals is to makeSubQuery easier to join and build with - and that includes much lower staking requirements.
Flexibility
SubQuery is just a tool in the hands of our community, endless opportunities exist limited only by the creativity of the people.
Some indexers, like Covalent and Unmarshal, are general purpose indexers that index standard datasets (e.g. transaction lists and blocks) and provide these indexed datasets to customers via some form of API. These services are great, they have a lot of data, and they are really quick to implement. The problem is that they have no flexibility, you can't change the shape of your data, and you can’t add more data that you need to make your dApp better. When building a unique application that is faster, more feature rich, and more intuitive than your competition, you need custom data from a Flexible indexer.
Both SubQuery and The Graph were designed to be flexible in a way that they act as a scaffold or framework for each developer’s own custom built API - devs have the freedom to adapt and transform decentralised data to suit their needs. They can also adapt these services to fit into their existing backends, interface directly with other data services like Big Query and Athena, connect to dashboards like Grafana or Metabase, or even download data to analyse in Excel!
SubQuery takes this flexibility a whole lot further than the Graph however, by giving the developers the power to retrieve data from external API endpoints, make non-historical RPC calls, and even import your own external libraries into your projects. For example, you could import real world data from a service like Coingecko, or pull data from another chain - with SubQuery you’re not limited by the sandbox!
Finally, even though the SubQuery Network is coming online soon, developers are still free to use the SubQuery Managed Service. SubQuery has no plans to retire the Managed Service, unlike the Graph’s solution which is scheduled for deactivation in 2023. Alternatively, self-hosting web3 builders can easily reconfigure their locally running Subquery project to tweak databases, query services, and other properties to optimise and scale their indexer in ways that no other indexer allows.
Speed
Speed is constantly an issue with indexing, and can be measured in three different ways.
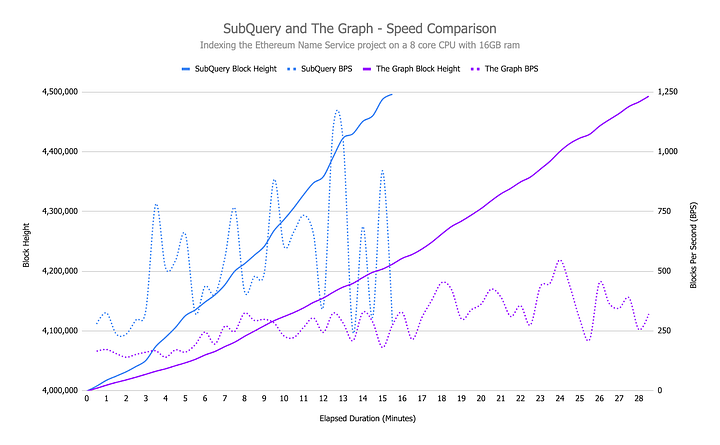
Indexing Speed: Both SubQuery and The Graph are designed to index data fast, but analysis shows that the existing beta support from SubQuery is already 1.85x faster for common projects over The Graph (e.g the standard Ethereum Name Service project). This adds up when you’re indexing millions of blocks, and is something to consider when choosing your indexer. SubQuery achieves this by using multi-threading and optimisation of the store to reduce costly database writes. With faster sync times, developers can iterate faster and deliver features to market quicker.
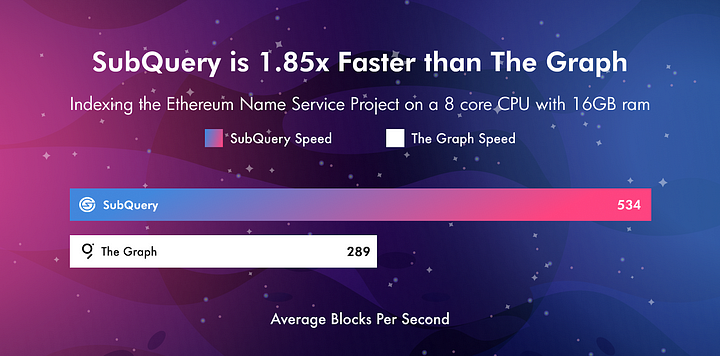
Both SubQuery and The Graph also have automated historical state management, allowing you to roll back your data to a particular block and only perform a partial reindex - this is a huge performance advantage over centralised indexers who require you to reindex your entire dataset on each and every change - making your development iterations much slower.
New Data Speed: Since indexers are an additional layer within your tech stack, one of the biggest challenges is the time between when an on-chain event occurs, and when the data is processed and able to be queried from the indexer. Centralised providers like Subsquid are slower at this, since the data needs to be pre-indexed in an archive first, before it is again indexed by your own project, and then before it can be queried by your dApp. Each of these steps mean that users have to wait seconds between doing something on a blockchain and it showing up in their UI - which could have a significant effect on your dApp’s performance!
The Graph and SubQuery on the other hand index directly from RPC providers, meaning one less step in the process. SubQuery takes this to the next level though, and for some networks, supports probabilistic indexing of unfinalised data. Most networks have a finalisation period that can range from 2 to 30 blocks. SubQuery skips this finalisation, and will take the most probabilistic data before it is finalised to provide to the app. In the unlikely event that the data isn’t finalised, SubQuery will automatically roll back and correct its mistakes quickly and efficiently - resulting in an insanely quick user experience for your customers.
Development Speed: Don’t forget this one, writing an ETL pipeline is complex and you want to get it right. Picking an indexer that is familiar to you and has a large amount of developer support is a critical consideration. Despite the large number of chains supported, SubQuery provides a prebuilt starter project for each and also has guided walkthroughs for indexing each chain on its website. This means there is no need to start from scratch and if the docs don’t have the answers, you’re always able to get support from the large Discord community or directly from the team in Telegram.
Universal Support
It is clear that developers are starting to think more about how they can deploy their dApp or protocol across multiple layer-1 networks to onboard customers in each space, and help interconnect web3 to encourage adoption. When deciding on your indexing infrastructure provider, you should also consider what chains they will support you on.
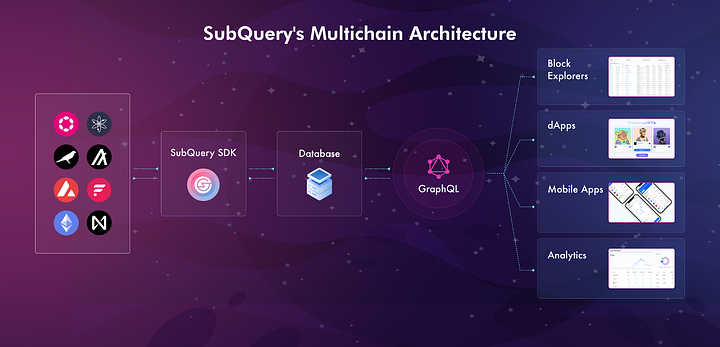
SubQuery’s origins in the Polkadot ecosystem required us to factor multi-chain support from the outset. After delivering world-class infrastructure services to all of the leading parachain teams as they grew from small teams to unicorns, SubQuery was confident we could offer the same experience to developers in other ecosystems.

In only the past year, SubQuery has added support for all of the leading non-ETH ecosystems, including Cosmos, NEAR, and Algorand. This support has also extended to the leading EVM chains and scaling solutions, including Ethereum, Avalanche, and Flare. In a matter of months, SubQuery has gone from a single-point offering to one that can handle the demands of developers in a myriad of ecosystems. In order to be the true universal Web3 data index toolkit, we plan to have the widest chain support of any indexer.

SubQuery has leveraged this advantage to also provide multi-chain indexing. This gives you the option to index data from across different networks into the same dataset, which in turn provides a single endpoint where you can query all of your data across all chains. For example, you could capture XCM transaction data from all Polkadot parachains or monitor IBC messages across Cosmos Zones in a single project, with a single database, and a single query endpoint. It means that SubQuery is truly a write once, run anywhere multi-chain indexer.
Of course, the principle of being ‘universal’ also applies to the decentralised network itself - The Graph’s Network still only supports a small subset of the layer-1s that their SDK supports and that results in developers in these other ecosystems not being able to benefit from the advantages of decentralisation. SubQuery’s stated goal is to launch the SubQuery Network with support for all layer-1s that its SDK supports, meaning there are no “second-class” chains with SubQuery.
Learn how to migrate from The Graph: https://academy.subquery.network/build/graph-migration.html
About SubQuery
SubQuery is a blockchain developer toolkit facilitating the construction of Web3 applications of the future. A SubQuery project is a complete API to organise and query data from Layer-1 chains. Currently servicing Ethereum, Polkadot, Avalanche, Algorand, NEAR, Cosmos and Flare projects, this data-as-a-service allows developers to focus on their core use case and front-end without wasting time building a custom backend for data processing activities. In the future, the SubQuery Network intends to replicate this scalable and reliable solution in a completely decentralised manner.
Linktree | Website | Discord | Telegram | Twitter | Matrix | LinkedIn | YouTube