

When we set out to build SubQuery, we always planned to make the developer experience as close as possible to other indexing solutions out there in the market, including The Graph. Following our recent Ethereum integration announcement, developers building on Ethereum can now benefit from the superior SubQuery experience, including the open-source SDK, tools, documentation, and developer support that the SubQuery ecosystem provides. Additionally, Ethereum is accommodated by SubQuery’s Managed Service, which provides enterprise-level infrastructure hosting and handles over hundreds of millions of requests each day.

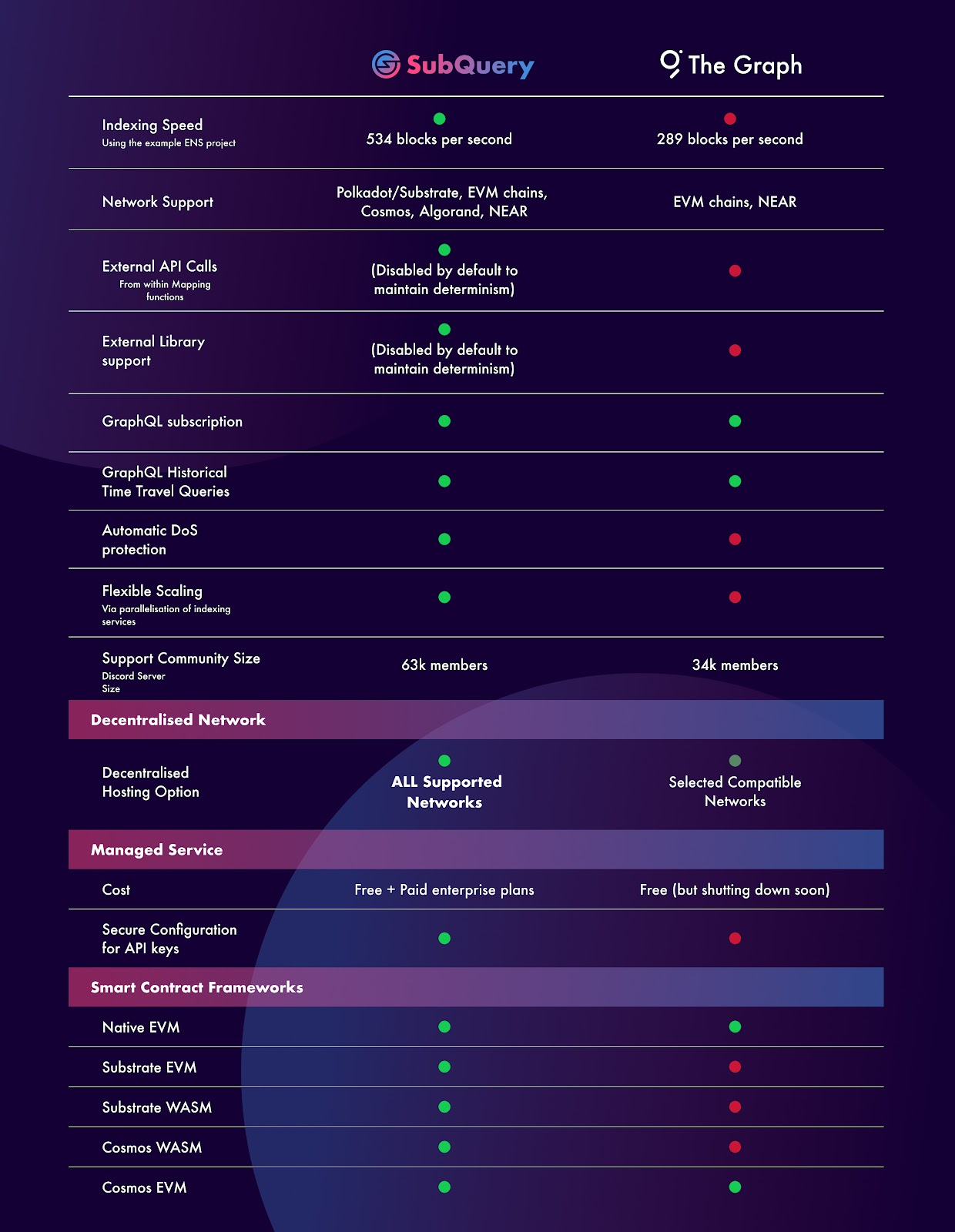
Both SubQuery and The Graph are designed to index data fast, but analysis shows that SubQuery is 1.85x faster for common projects over The Graph (e.g the standard Ethereum Name Service project). This adds up when you’re indexing millions of blocks, and is something to consider when choosing your indexer. SubQuery achieves this by using multi-threading and optimisation of the store to reduce costly database writes. With faster sync times, developers can iterate faster and deliver features to market quicker.
SubQuery also brings some major improvements to existing users of The Graph, including the ability to make external API calls or import external libraries from within your mapping functions and better controls to run your projects in your own infrastructure with automated DOS (denial of service) mitigation controls. Additionally, we have no plans to sunset our managed service.
To read a detailed comparison of SubQuery and other popular indexers, check out our recent article on Comparing Data Indexers.
The migration from a SubGraph to a SubQuery Project is (by design) easy and quick. It may take you an hour or two to complete the migration, depending on the complexity of your SubGraph.
Want Support During Migration? Reach out to our team at sales@subquery.network and get professional service to manage the migration for you.
Prefer to watch our Sean Au explain how to migrate from The Graph in a video? Watch it below!
Migration Overview
- Both SubGraph and SubQuery use the same schema.graphql file to define schema entities. In addition, both have similar sets of supported scalars and entity relationships (SubQuery adds support for JSON types though).
- The manifest file shows the most differences but you can easily overcome these differences once you understand them.
- In addition, Mapping files are also quite similar with an intentionally equivalent set of commands, which are used to access the Graph Node store and the SubQuery Project store.
GraphQL Schema
Both SubGraphs and SubQuery projects use the same schema.graphql to define entities.
Visit this full documentation for schema.graphql. You can copy this file from your SubGraph to your SubQuery project in most cases.
Notable differences include:
- SubQuery does not have support for Bytes (use String instead) and BigDecimal (use Float instead).
- SubQuery has the additional scalar types of Float, Date, and JSON (see JSON type).
- Comments are added to SubQuery Project GraphQL files using hashes (#).
- SubQuery does not yet support full-text search.
Manifest File
The manifest file contains the largest set of differences, but once you understand those they can be easily overcome. Most of these changes are due to the layout of this file, you can see the full documentation of this file here.
Notable differences include:
- SubQuery has a section in the manifest for the network:. This is where you define what network your SubQuery project indexes, and the RPC endpoints (non-pruned archive nodes) that it connects to in order to retrieve the data. Make sure to include the dictionary: endpoint in this section as it will speed up the indexing speed of your SubQuery project.
- Both SubGraphs and SubQuery projects use the dataSources: section to list the mapping files.
- Similarly, you can define the contract ABI information for the smart contract that you are indexing.
- In SubQuery, this is under the options: property rather than source:.
- In both, SubQuery and SubGraph, you import a custom ABI spec that is used by the processor to parse arguments. For SubGraphs, this is done within the mapping: section under abis:. For a SubQuery project, this is at the same level of options: under assets: and the key is the name of the ABI.
- In a SubQuery project, you can document both block handlers, call handlers, and event handlers in the same mapping: object.
- In a SubQuery project, you do not list all mapping entities in the project manifest.
- Handlers and Filters - Each mapping function is defined slightly differently in a SubQuery project:
- Instead of listing the blocks/events/calls as the key and then denoting the handler that processes it. In SubQuery, you define the handler as the key and then what follows is the description of how this handler is triggered.
- In a SubQuery project, you can document both block handlers, call handlers, and event handlers in the same mapping: object, the kind: property notes what type we are using.
- SubQuery supports advanced filtering on the handler. The format of the supported filter varies amongst block/events/calls/transactions, and between the different blockchain networks. You should refer to the documentation for a detailed description of each filter.


Codegen
The codegen command is also intentionally similar between SubQuery and SubGraphs
All GraphQL entities will have generated entity classes that provide type-safe entity loading, read and write access to entity fields - see more about this process in the GraphQL Schema. All entites can be imported from the following directory:

For ABI's registered in the project.yaml, similar type safe entities will be generated using npx typechain --target=ethers-v5 command, allowing you to bind these contracts to specific addresses in the mappings and call read-only contract methods against the block being processed. It will also generate a class for every contract event to provide easy access to event parameters, as well as the block and transaction the event originated from. All of these types are written to src/types directory. In the example Gravatar SubQuery project, you would import these types like so.

Mapping
Mapping files are also quite identical to an intentionally equivalent set of commands, which are used to access the Graph Node store and the SubQuery Project store.
In SubQuery, all mapping handlers receive a typed parameter that depends on the chain handler that calls it. For example, an ethereum/LogHandler will receive a parameter of type EthereumLog and avalanche/LogHandler will receive a parameter of type AvalancheLog.
The functions are defined the same way. Moreover, entities can be instantiated, retrieved, saved, and deleted from the SubQuery store in a similar way as well. The main difference is that SubQuery store operations are asynchronous.
SubGraphSubQuery

Querying Contracts
We globally provide an api object that implements an Ethers.js Provider. This will allow querying contract state at the current block height being indexed. The easiest way to use the api is with Typechain, with this you can generate typescript interfaces that are compatible with this api that make it much easier to query your contracts.You can then query contract state at the right block height. For example to query the token balance of a user at the current indexed block height (please note the two underscores in Erc20__factory):

The above example assumes that the user has an ABI file named erc20.json, so that TypeChain generates ERC20__factory class for them. Check out this example to see how to generate factory code around your contract ABI using TypeChain
What's Next?
Now that you have a clear understanding of how to build a basic SubQuery project, what are the next steps of your journey?
Now, you can easily publish your project. SubQuery provides a free Managed Service where you can deploy your new project. You can deploy it to SubQuery Managed Service and query it using our Explorer. Read this complete guide on how to publish your new project to SubQuery Projects.
To dive deeper into the developer documentation, jump to the Build section and learn more about the three key files: the manifest file, the GraphQL schema, and the mappings file.
If you want to practice with more real examples, then head to our Courses section and learn important concepts with related exercises and lab workbooks. Get access to readily available and open-source projects, and get hands-on experience with SubQuery projects.
In the end, if you want to explore more ways to run and publish your project, refer to Run & Publish section. Get complete information about all the ways to run your SubQuery project, along with advanced GraphQL aggregation and subscription features.
Summary
As you can clearly see, it's only a small amount of work to migrate your SubGraphs to SubQuery. Once completed, you can take advantage of SubQuery's absolute performance. Now, start iterating and delivering faster with quicker sync times and indexing optimisations to ensure that you always have fresh data.
Moreover, SubQuery is multi-chain by design. Hence, the same project can be easily extended across chains and the SubQuery Network supports them all. Indexing across different chains is incredibly easy with SubQuery's unified design.
Finally, be assured that we're right behind you. Thousands of supporters and builders on our Discord server can provide you with the technical support that you need. Additionally, please reach out via support@subquery.network, we'd love to chat, hear what you're building, and work with you to make your migration easier.
About SubQuery
SubQuery is a blockchain developer toolkit facilitating the construction of Web3 applications of the future. A SubQuery project is a complete API to organise and query data from Layer-1 chains. Currently servicing BNB, Ethereum, Polygon, NEAR, Polkadot, Avalanche, Algorand, Cosmos and Flare projects, this data-as-a-service allows developers to focus on their core use case and front-end without wasting time building a custom backend for data processing activities. In the future, the SubQuery Network intends to replicate this scalable and reliable solution in a completely decentralised manner.
Linktree | Website | Discord | Telegram | Twitter | Matrix | LinkedIn | YouTube