

Welcome back for another instalment of the SubQuery Mastery Series, where we help you navigate the SubQuery Network and ensure you maximise potential rewards. If you’re reading this article, hopefully, you already know about SubQuery and are interested in indexed on-chain datasets (in a completely decentralised manner!)
This article is for all the dApp developers building cutting-edge web3 applications that want to focus on their core use case instead of building and maintaining infrastructure, that’s where we come in. The SubQuery Network hosts indexed on-chain data that can be served to your dApps in a completely decentralised way. This guide will walk you through the steps to find and access the on-chain data that you need to query.
If you want to explore the SubQuery Network comprehensively (more than what we explain here), you can visit our SubQuery Network Documentation.
Where to find SubQuery Network indexed datasets?
To find the already available indexed datasets on the SubQuery Network, you can head to our Network app and go to the Explorer. Alternatively, you can go directly by clicking this link: https://app.subquery.network/explorer/home.
Behind these indexed datasets (termed ‘SubQuery Projects’) is a network of independent data indexers operating around the world in a decentralised, trustless, and unstoppable way.
In the Explorer you can type in a network or project of your choice to see if the data of interest is available. For example, if you type in ‘Aleph Zero’ you’ll find there are two SubQuery Projects with Aleph Zero data which may fit your needs perfectly. You can also see how many indexers are serving requests for this project - in the case of the Nova Wallet Aleph Zero project, there are 12 globally distributed indexers (Node Operators) servicing this project.
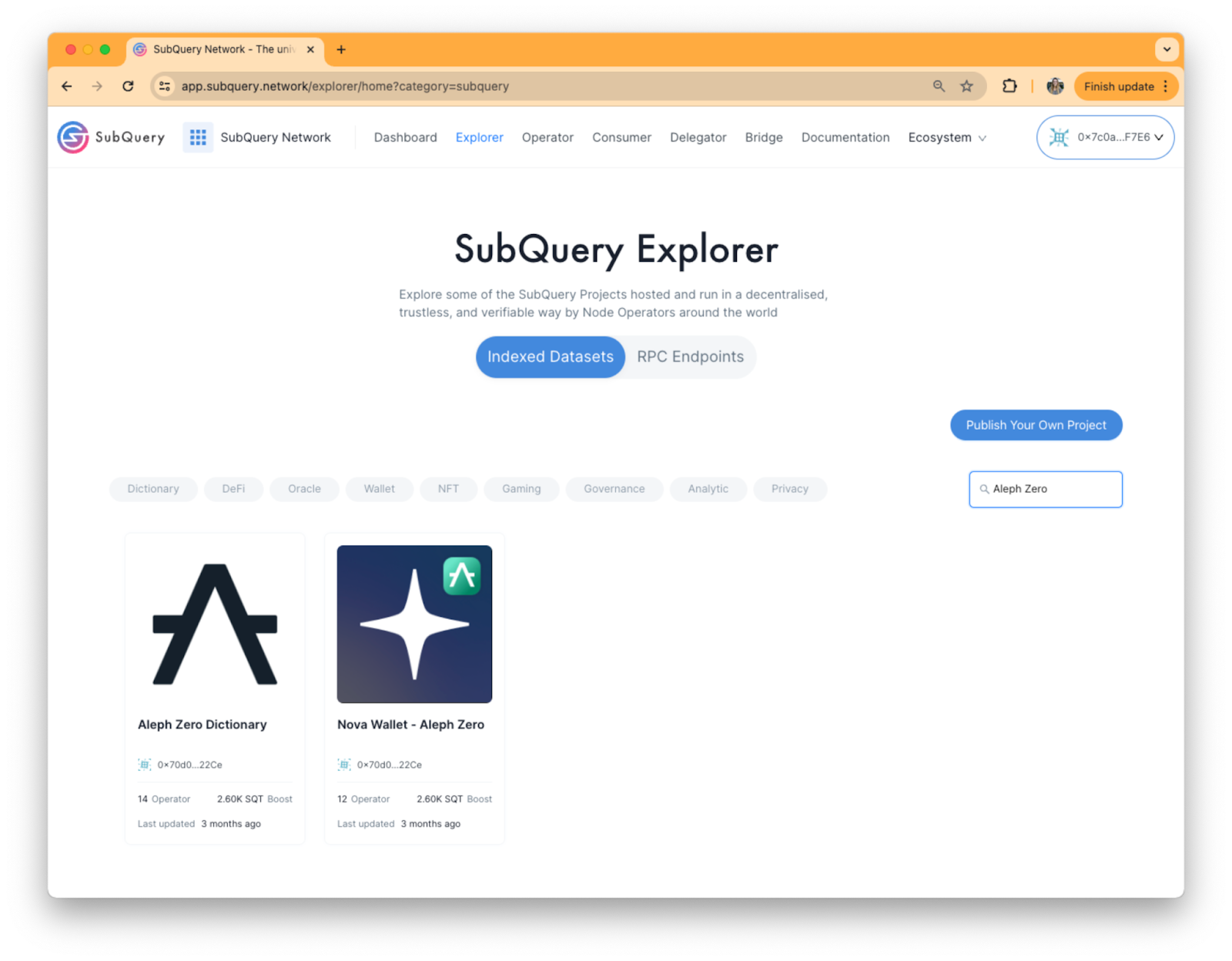
You can click on a SubQuery project of interest to see if it has all the required data. For example in the dataset below, you can use it to easily fetch operation history & analytics data on the Aleph Zero network.
If you’ve found the dataset that suits your needs, head straight to this article's ‘Purchasing Indexed Data’ section.
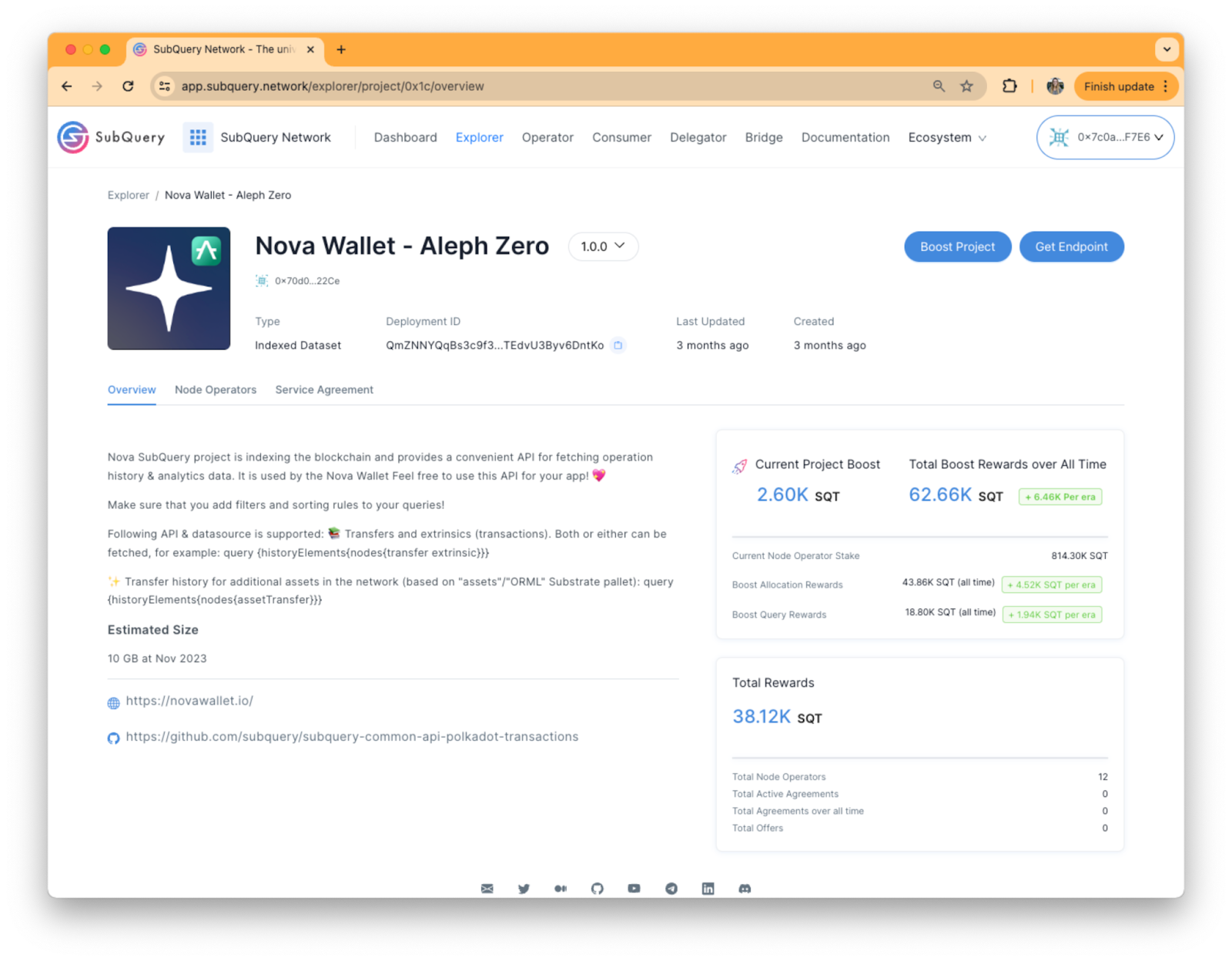
How to add your dataset to the SubQuery Network
The SubQuery Network can host SubQuery Projects (indexers built using the SubQuery SDK) and Subgraphs (indexers built using the Graph SDK). Both are easy to deploy to the SubQuery Network by following the steps below.
SubQuery Projects
To build a dataset for your dApps requirements, head to the detailed SubQuery Documentation to get started. We have step-by-step guides and starter projects (boilerplate templates) for a huge amount of supported networks.
If the network you require data for is EVM compatible and not yet supported, we can quickly add support. Simply fill out this form.
Once your SubQuery Project is ready, head back to the Network Explorer and select ‘Publish Your Own Project’, and then go for the ‘SubQuery Project’ option.

Publish your project to IPFS first by following the guide here. Then enter the project CID and give your project a name.
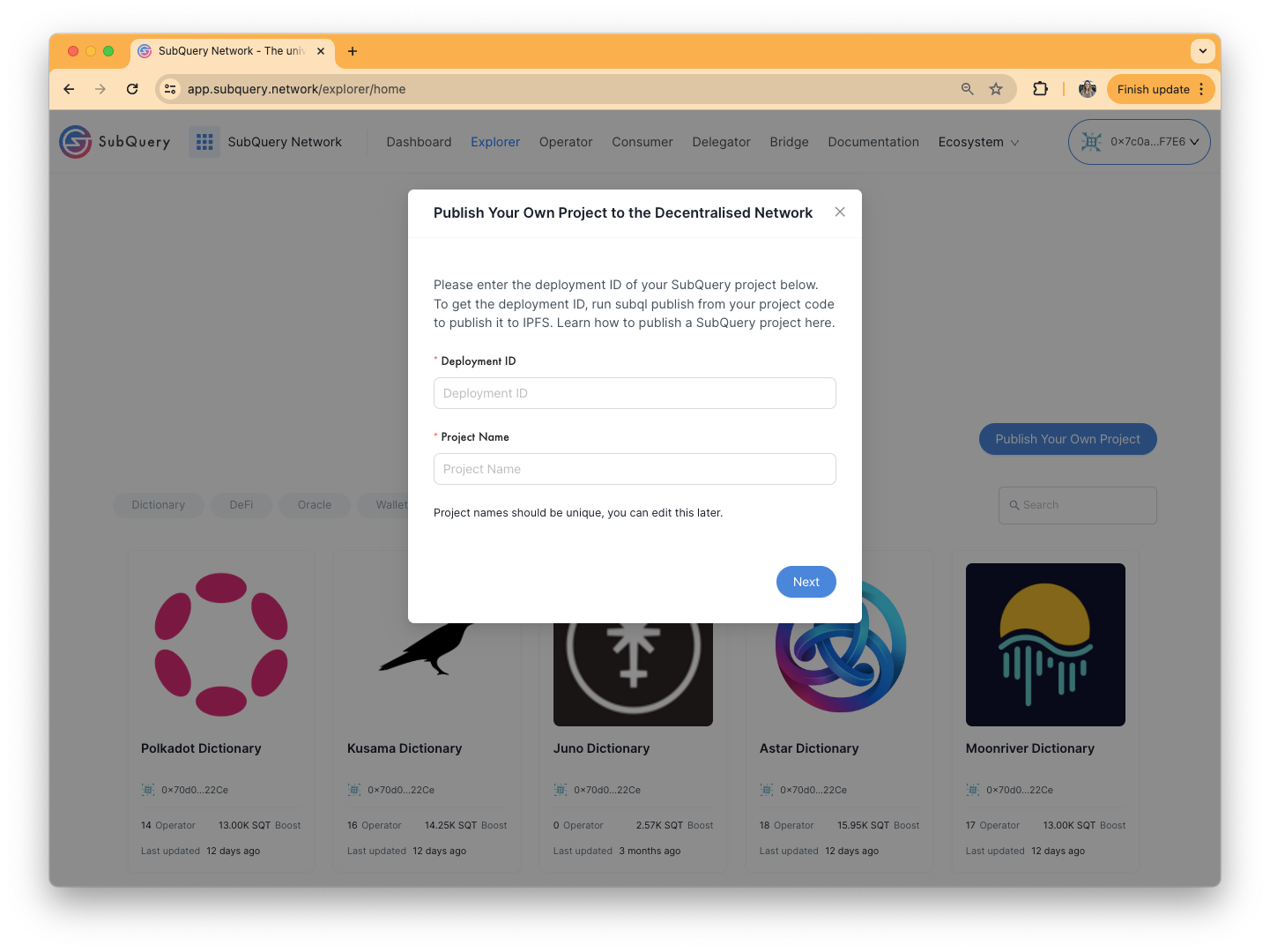
On the next page you are asked to enter a project description, and also populate information about the project that Consumers or Node Operators might find interesting. This includes:
- A logo or image
- Categories that the project can be classified by
- A website address for the project
- A link to where the source code can be found
- The deployment version number
- The deployment description, which might include additional information for Node Operators about migration steps or breaking changes in this version
Once entered, click "Publish" to publish your project. You will then be taken to a page to manage your project. You can easily make changes to your project or deploy a new version by accessing the Managed Project page.
Subgraphs
Similarly to a SubQuery Project, in order to publish a Subgraph project to the SubQuery Network, you must first upload it to IPFS and retrieve a publicly accessible IPFS CID.
There are two ways to do this. First, if the Subgraph is already live on the Graph Network, you can retrieve the IPFS CID from the Graph Explorer. In the Graph Explorer this value is called the Deployment ID on the website, or the ipfs_hash when running it on a Graph node.
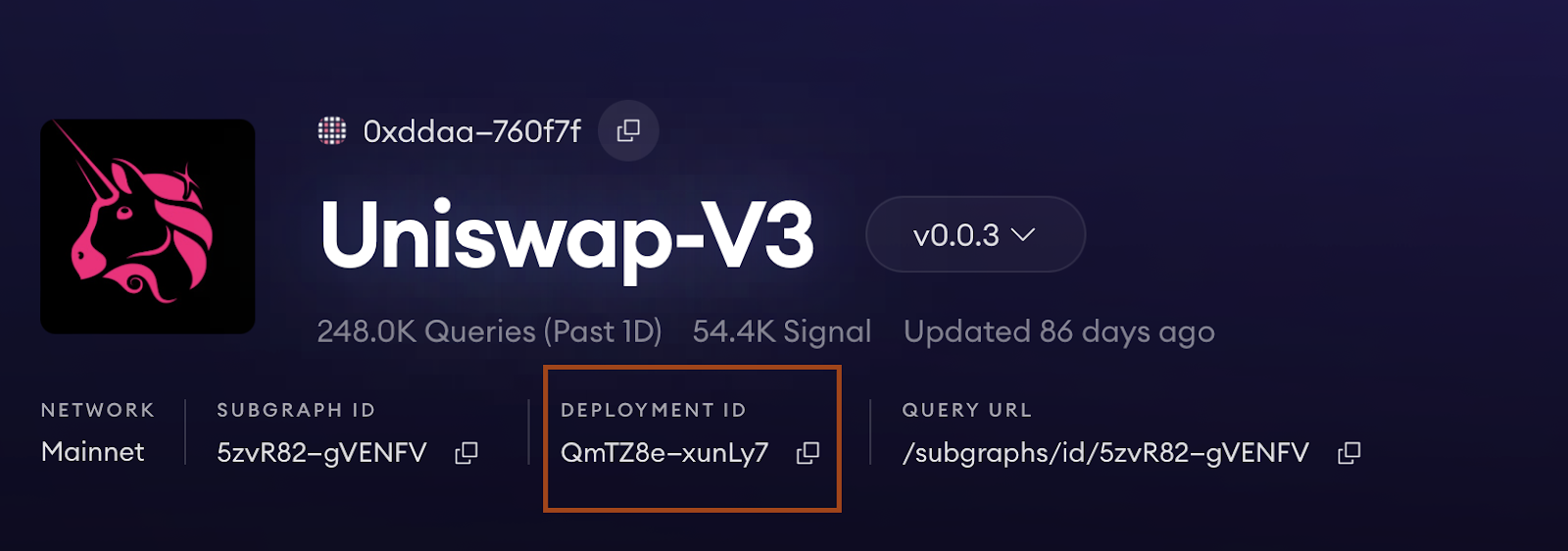
Alternatively, if you have not deployed the Subgraph project on the Graph Network, you can use the Graph's command line interface: graph build -i https://unauthipfs.subquery.network/ipfs/api/v0. This will return you an IPFS CID that you can use.
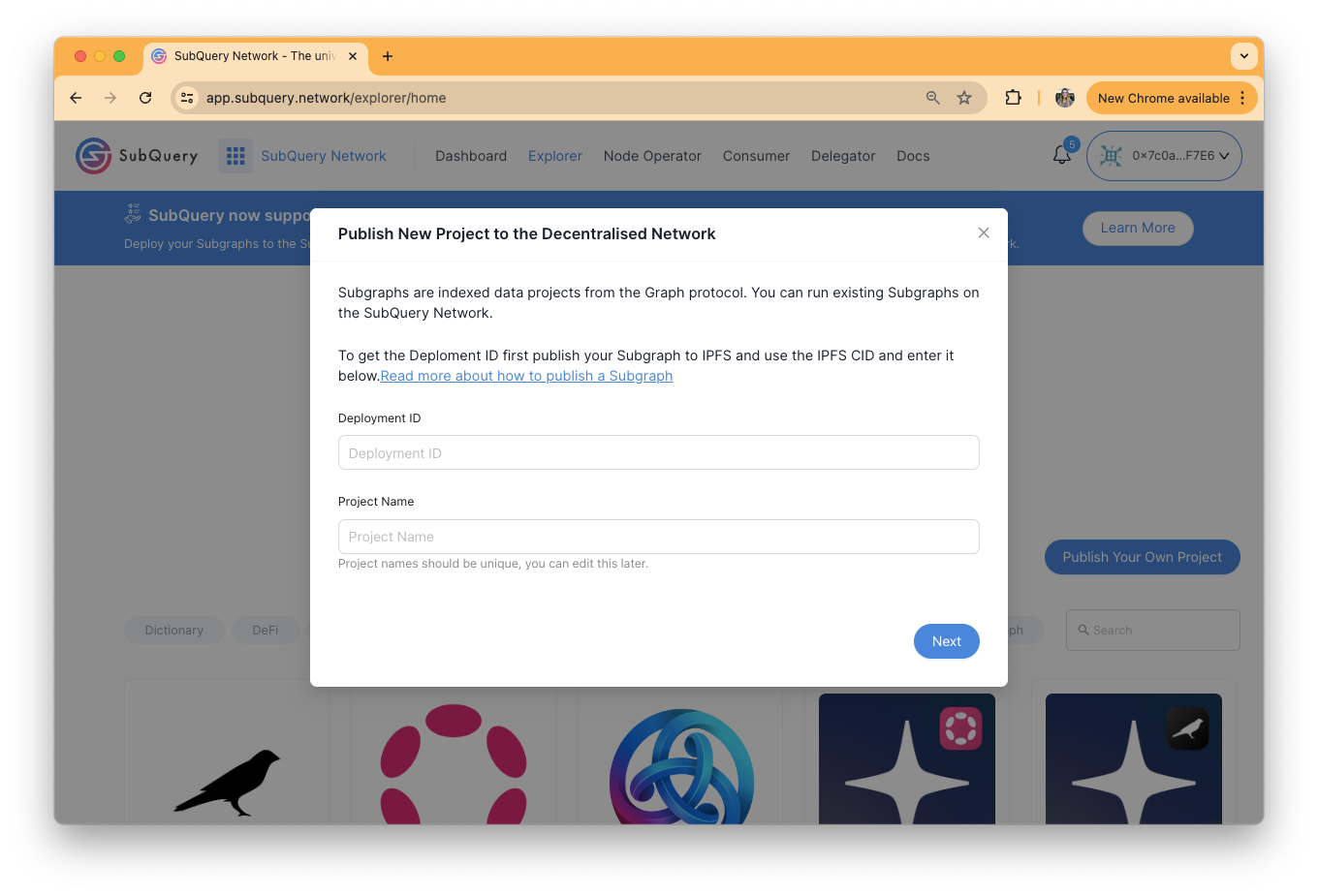
On the next page you are asked to enter a project description, and also populate information about the project that Consumers or Node Operators might find interesting.
Once entered, click "Publish" to publish your project. You will then be taken to a page to manage your project where you can monitor and make changes to your project.
ℹ️ How to encourage Node Operators to sync your project
At this stage you should reach out to Node Operators in our Discord to encourage them to start syncing it, once they do you will be able to create plans and start querying this data. You might also want to consider boosting your project to incentivise Node Operators to do so, and in return receive free queries to it.
Purchasing Indexed Data
Now that you’ve located your existing dataset on the SubQuery Network, or you’ve built your own and published it to the network, it’s time to create a plan to query the data.
Our Flex plan creation process is as streamlined as possible and is similar to any centralised alternative, it only takes a few minutes before you have an API key and a single production endpoint that you can query through.
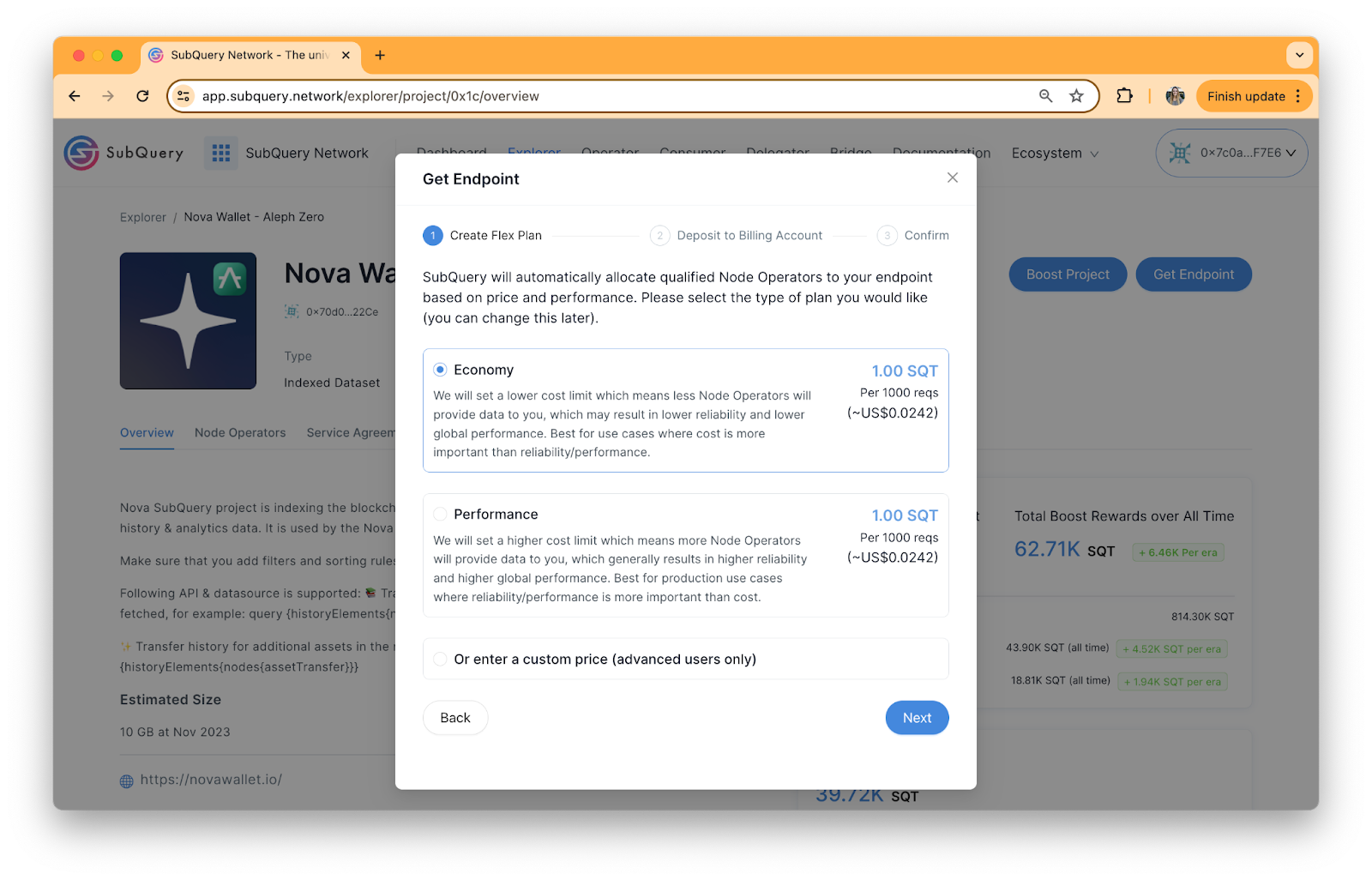
1. Choose Your Plan Type
After signing a request in your wallet and selecting ‘Get Endpoint’ on your chosen SubQuery Project you can begin the Flex Plan creation process. You have the option to choose between Economy, Performance or make your own custom plans. Each of these are summarised below.
- Economy:
- Cheaper
- Less attractive to indexers
- Less reliable
- Lower global performance
- Best used where costs is more important than reliability/performance
- Performance:
- More expensive
- More attractive to indexers
- Higher reliability
- Higher global performance
- Best used for production-level apps where reliability/performance is more important than cost
- Custom:
- Only for advanced users with a unique use case
- Flexible - the price per thousand requests and maximum number of indexers is discretional
- May be used in cases where a consumer wants to pay even more than the Performance plan to guarantee maximum indexers, where cost is not a concern
SubQuery will automatically allocate qualified Node Operators to your endpoint based on the price and performance you select.
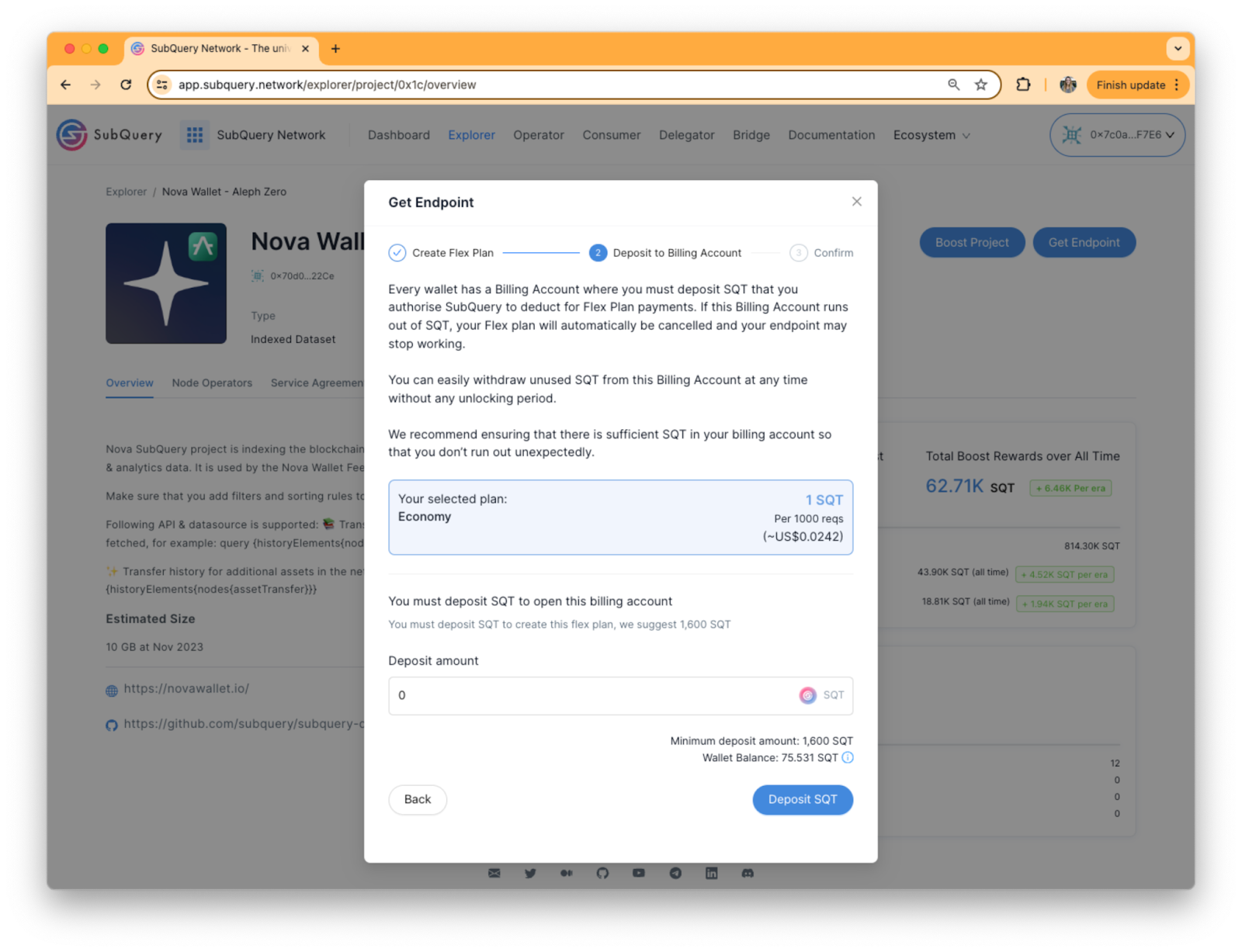
2. Deposit to Billing Account
After choosing your Flex Plan type, you are required to deposit SQT to your Billing Account. Once your Billing Account is topped up, you authorise SubQuery to deduct Flex Plan payments from the account. It’s important not to let your billing account run out of SQT as your Flex plan will automatically be cancelled and your endpoint may stop working. Rest assured, you will receive notifications on the SubQuery Network app when your account balance is running low.
You can also easily withdraw unused SQT from this Billing Account at any time without any unlocking period.
3. Confirm
Once you’ve chosen your Flex Plan type and topped up your Billing Account, you will be prompted to sign and approve a number of transactions. Please follow the steps shown on the page to do so using your connected wallet. Then, voila, you will have access to your decentralised indexed on-chain data!
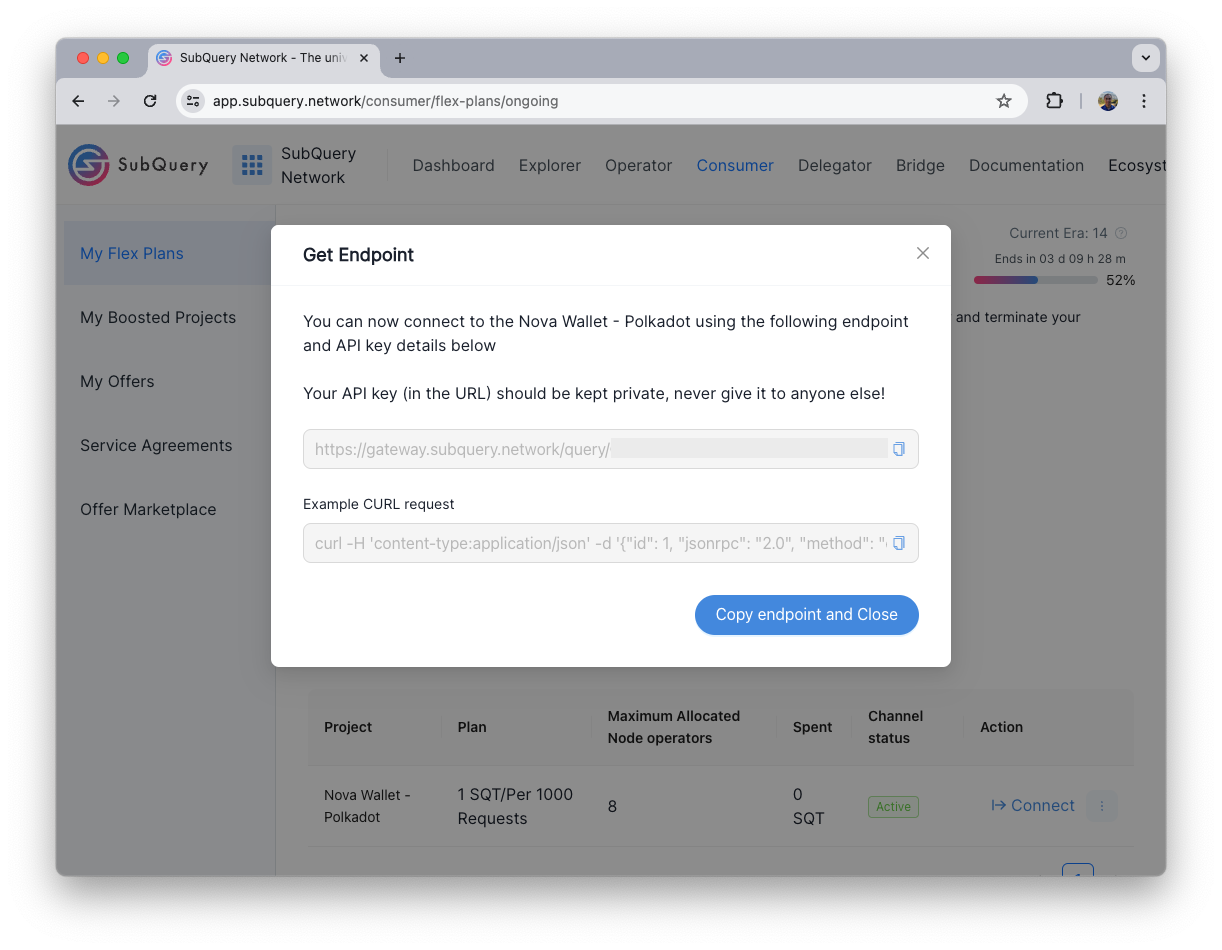
View and Access Endpoint and API key
You can view your personalised endpoint and API key on the final step. This allows you to connect to the endpoint and make queries through SubQuery's Gateway. You can also get the endpoint by navigating to Consumer > My Flex Plans.
This endpoint acts like any other endpoint that you would use for API or RPC calls. An example query is also provided to try out. API keys can either be sent as a query parameter (https:://your.endpoint.url/?apikey=<APIKEY>) or as a request header ('apikey': '<APIKEY>').
What role am I playing in the SubQuery Network?
By obtaining indexed data from the SubQuery Network you are acting as a Consumer. A Consumer is either an individual or an organisation that pays for processed and organised blockchain data and/or RPC queries from the SubQuery Network. Consumers effectively make requests to the SubQuery Network for specific data and pay an agreed amount of SQT in return.
What are the benefits of decentralised indexers?
If you’re reading this article, it’s likely you already highly value decentralisation and understand the importance of eliminating a single point of failure in your tech stack when using a centralised infrastructure provider. As a Consumer, you can interact with completely decentralised indexers from the SubQuery Network for your dApps. Other benefits include:
- Faster performance for your dApps. Since your dApps can get data from a decentralised network of data indexers, the average latency will be lower and performance higher
- Higher reliability. Due to the decentralised nature of the network, your dApp can immediately fall back to an alternative when an indexer goes offline.
- Focus on developing your application, not on running blockchain infrastructure.
- Cost-effective. Combining the two points above, consuming data from SubQuery results in a very cost-effective way to power your applications.
Ready to access decentralised data?
Once you have some SQT in your favourite wallet, head to the SubQuery Network app and get started.
About SubQuery
SubQuery Network is innovating web3 infrastructure with tools that empower builders to decentralise the future. Our fast, flexible, and open data indexer supercharges dApps on over 200 networks, enabling a user-focused web3 world. Soon, our Data Node will provide breakthroughs in the RPC industry, and deliver decentralisation without compromise. We pioneer the web3 revolution for visionaries and forward-thinkers. We’re not just a company — we’re a movement driving an inclusive and decentralised web3 era. Let’s shape the future of web3, together.
Linktree | Website | Discord | Telegram | Twitter | Blog | Medium | LinkedIn | YouTube





