
Authors: Ian He and James Bayly from SubQuery
Overview of SubQuery Sharded Data Node
The SubQuery Sharded Data Node, herein referred to as Sharded Data Node, represents a novel category of chain nodes, developed and maintained by the SubQuery team, for various network clients, starting from Geth. The purpose of these nodes is to develop a more performant RPC that is easily decentralised, and while doing this we realised that this novel solution would also help solve the problems raised by EIP-4444.
The foundational objective of Sharded Data Node is to offer an economically efficient and more performant alternative to conventional archival RPC nodes, enabling operation on lower-specification machines, requiring less storage, and thereby facilitating decentralisation away from dominant entities. The codebase will be public and open source (GPLv3), so the code can be reviewed, verified and built by the community.
The Data Node
The Sharded Data Node builds on the SubQuery Data Node. The performance limitations of data indexers and many other applications have long been limited by the RPC endpoint. Developers have long focussed on building nodes to ensure efficient validation to ensure the safety of the network. As a result of this sacrifice, RPCs calls can be inefficient and detrimental to the performance of dApps.
The SubQuery Data Node is an enhanced and heavily-forked RPC node (starting with the Geth client) that is perfectly optimised for querying, especially on endpoints like eth_getLog. Further, it will have the ability for clients to filter transactions in a single RPC call.
The Data Node will be open source (GPLv3), allowing people to contribute, extend, verify, or fork the implementation in any way.
The Sharded Data Node
EIP-4444 focuses on the sheer size of the node - an Ethereum archive requires about ~12 TB on Geth. This is an incredible cost that limits these nodes to large centralised infrastructure providers. THis problem is only exacerbated by time and with the rise of layer-2s and other scaling solutions.
SubQuery believes that in order to drive decentralisation of RPCs, you need to be able to make running these nodes easier and more accessible to everyday users. Currently the storage is made smaller by pruning data, which is intentionally discarding older information while cryptographically confirming that the recent data that is valid. This works fine for writing transactions, but means that indexers and other services are unable to query old data.
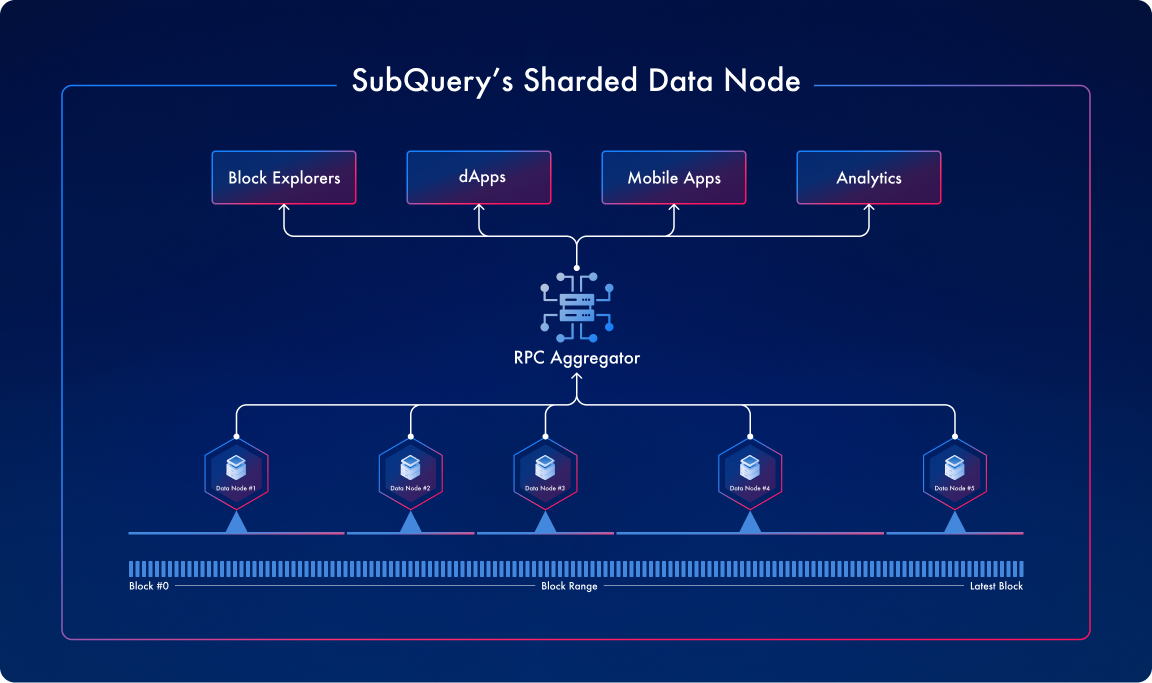
SubQuery will extend its Data Node to support sharding, that is making each Data Node smaller by splitting up block ranges between node operators. Since SubQuery’s Data Node only runs within the boundaries of a specific block range, it does not need to constantly sync new data, allowing it to optimise further for query performance rather than validation and verification.
Besides the standard RPC interface a normal RPC node and Data Node supports, A Sharded Data Node will also extend the Data Node to add endpoints that expose the block range of data/state it maintains. Significantly, the Sharded Data Node need not encompass historical chain state when functioning as a full node. This article, however, will exclusively discuss the Sharded Data Node in the context of an archive node.
The SubQuery Sharded node won’t just shard historical data, but also shard the historical state within the node. In other words, some modes of Sharded Data Node may not offer full functionality like a normal client if used alone, but combined together they can offer equivalent functionality and are more economically affordable.
This is where the SubQuery’s Sharded Data Node approach differs, these Sharded Data Nodes nodes will be optimised to run on the decentralised SubQuery Network, and the network will be designed to combine all these Sharded Data Nodes to expose a single unified endpoint that appears to cover the entire historical state of the chain. Developers will benefit from the entire historical state of the given network, and node operators will benefit from significantly lower running costs, creating a more cost efficient Ethereum network.
Variants
SubQuery’s roadmap includes several variants of Sharded Data Nodes, each of them requiring different size of storage and have limited feature when used alone:
Note that to construct a fully functional full node you require:
- An RPC aggregator that the SubQuery Network will provide
- A combination of Mode 1 nodes (covering all heights)
- At least one Mode 5 node.
To construct a fully functional archive node you require:
- An RPC aggregator that the SubQuery Network will provide,
- A combination of Mode 1 nodes (covering all heights), and
- A node with head data (Modes from 2 to 5)
Alternatively, you can create a fully functional archive node exclusively with Mode 2 nodes (covering all heights).
Execution Capability
The distinct feature of the Sharded Data Node is its execution capability, which differentiates it from alternative solutions for archiving historical data. Utilising a fork of the official chain client, it achieves maximum compatibility with a standard node.
If we categorise RPCs into different groups, different mode of Sharded Data Node offers different level of compatibility
- History Methods
- eth_getBlockTransactionCountByHash
- eth_getBlockTransactionCountByNumber
- eth_getUncleCountByBlockHash
- eth_getUncleCountByBlockNumber
- eth_getBlockByHash
- eth_getBlockByNumber
- eth_getTransactionByHash
- eth_getTransactionByBlockHashAndIndex
- eth_getTransactionByBlockNumberAndIndex
- eth_getTransactionReceipt
- eth_getUncleByBlockHashAndIndex
- eth_getUncleByBlockNumberAndIndex
- State Methods
- eth_getBalance
- eth_getCode
- eth_getStorageAt
- eth_getTransactionCount
- eth_call
- Gossip Methods
- eth_blockNumber
- eth_sendRawTransaction
- Miscellaneous Methods (not otherwise specified)
Sharded Data Node with Head data (mode 2~5) supports State Methods with block parameter ‘Latest’, and all Gossip Methods.
Sharded Data Node with Full History data (mode 3,4) supports all History Methods, while Partial History Data (mode 1,2,5) only supports some of History Methods plus the requested data is in the range the node holds. The requester should first call the capacity rpc we add to Sharded Data Node to get a better understanding of the meaning of certain rpc response, e.g getBlockByHash returns empty, whether it means the block hash not exist entirely or it not exist only between a certain range of blocks.
The RPC Aggregator
The Sharded Data Node requires the implementation of a new RPC aggregator to act as a proxy to a network of different Sharded Data Nodes. The primary function of the proposed RPC aggregator is to route requests to the appropriate Sharded Data Node based on the method and its parameters. This may necessitate transforming the original request into multiple requests directed to different Sharded Data Nodes and aggregating the results, or rejecting the request and requesting alternative parameters that align with the Sharded Data Node block segments.
SubQuery also plans to build this aggregator and release the source code as open source (GPLv3), so the code can be reviewed, verified and built by the community.
Data Synchronisation
The data synchronisation strategy for the Sharded Data Node is segmented into several phases, acknowledging the uncertainties surrounding the implementation of EIP-4444. Presently, as all historical data remains accessible via the peer-to-peer network of nodes, each Sharded Data Node will participate in this network for block synchronisation and contribution.
Post EIP-4444, despite the potential absence of historical blocks in standard nodes, Sharded Data Nodes will continue to provide historical data, sourcing it from peers who, like us, continue to offer it.
In the final phase, the establishment of a separate peer-to-peer network for the exchange of these historical data is envisioned. We plan to develop adapters to leverage all available data sources built by other projects for data availability.
State Sharding
SubQuery believes the centralization of archive nodes poses a significant challenge to the goal of web3. Therefore, state sharding is prioritised as a crucial feature from the outset. Modes 1 to 3 of Sharded Data Nodes are designed to possess shards of chain states.
A distinguishing aspect of Sharded Data Nodes is their self-awareness regarding the data they hold. Unlike standard nodes that imply complete historical or state data for archive nodes, the situation for Sharded Data Nodes is more complex. Not only do the results vary across different Sharded Data Node modes, but they also evolve based on administrative modifications. New RPC endpoints will be developed to reveal a sharded node’s data status, enabling a RPC aggregator to effectively manage required aggregation and routing in real-time. When a new Sharded Data Node joins the network, it should be discoverable from the RPC aggregator without administrative input. In other words, the RPC aggregator should be able to actively monitor the new Sharded Data Node and collect an up to date range of blocks which are available on each node.
The integrity of the states is maintained analogously to standard nodes, with states computed through the execution of each block, akin to a normal chain client. Subsequently, the data is tailored for compactness and storage efficiency.
Data Availability and Incentivization
In order to ensure node operators run different Sharded Data Nodes that sufficiently cover the entire chain state and history, we propose a unique incentive structure. This incentive structure could initially be segmented by fixed block ranges, and then take into account the number of existing node operators that are serving data for that segment. This approach would motivate operators to cover block ranges with less existing node operators (and therefore lower redundancy), thereby aligning goals of reliability with reward maximisation. This mechanism, a baseline reward for serving a certain block range, could be complemented with additional rewards for serving requests.
In the longer term, we could remove the concept of fixed block ranges and allow node operators to choose their own range. We could then weight blocks individually based on the number of existing node operators that are serving data for that block, and derive a total baseline reward based on the sum of these weights.
Despite the incentivization structure, situations may arise where no network peers possess certain historical block ranges. In such cases, we could resort to a 'cold archive' solution for block retrieval and node reconstruction. This may be independently developed or in collaboration with other projects.
Summary
The SubQuery Sharded Data Node (Sharded Data Node) is a specialised chain node proposed and developed by SubQuery, offering a lower cost alternative to traditional archive nodes designed to facilitate further decentralisation of RPCs. It could operate in different modes, each providing different levels of historical and state data. The system requires RPC aggregators to route requests based on data availability across different Sharded Data Nodes.
Data synchronisation is planned in phases, considering potential blockchain updates like EIP-4444. State sharding is a crucial feature, addressing archive node centralisation concerns by distributing state data across nodes. Sharded Data Node's design ensures compatibility with official chain clients and includes mechanisms for data integrity and efficient storage. The network incentivizes node operators based on data provision and availability, with fallback solutions for retrieving unavailable historical blocks.
The foundational objective of Sharded Data Node is to offer an economically efficient and more performant alternative to conventional archival RPC nodes, enabling operation on lower-specification machines, requiring less storage, and thereby facilitating decentralisation away from dominant entities. The codebase will be public and open source (GPLv3), so the code can be reviewed, verified and built by the community.
About SubQuery
SubQuery Network is innovating web3 infrastructure with tools that empower builders to decentralise the future. Our fast, flexible, and open data indexer supercharges dApps on over 125 networks, enabling a user-focused web3 world. Soon, our Data Node will provide breakthroughs in the RPC industry, and deliver decentralisation without compromise. We pioneer the web3 revolution for visionaries and forward-thinkers. We’re not just a company - we’re a movement driving an inclusive and decentralised web3 era. Let's shape the future of web3, together.
Linktree | Website | Discord | Telegram | Twitter | Blog | Medium | LinkedIn | YouTube