Today we are proud to announce our new improvement to SubQuery, SubQuery’s Dictionary indexing feature.
The SubQuery Dictionary is all about speeding up your Projects. It dramatically improves indexing the performance of your SubQuery Project, sometimes up to 10x faster.
When indexing chain data, SubQuery Projects used to inspect each block. Polkadot’s chain is large, 130GB of unstructured data over almost 6 million blocks. This takes many hours to index, time that you don’t want to wait for — especially when testing.
SubQuery projects now have the option to skip all this, we essentially pre-index the location of all events within a chain.
Performance is improved the most when the data is not a common occurrence, but instead interspersed along the chain, as if the data is rare, the Dictionary skips more blocks, and therefore the impact on performance is greater.
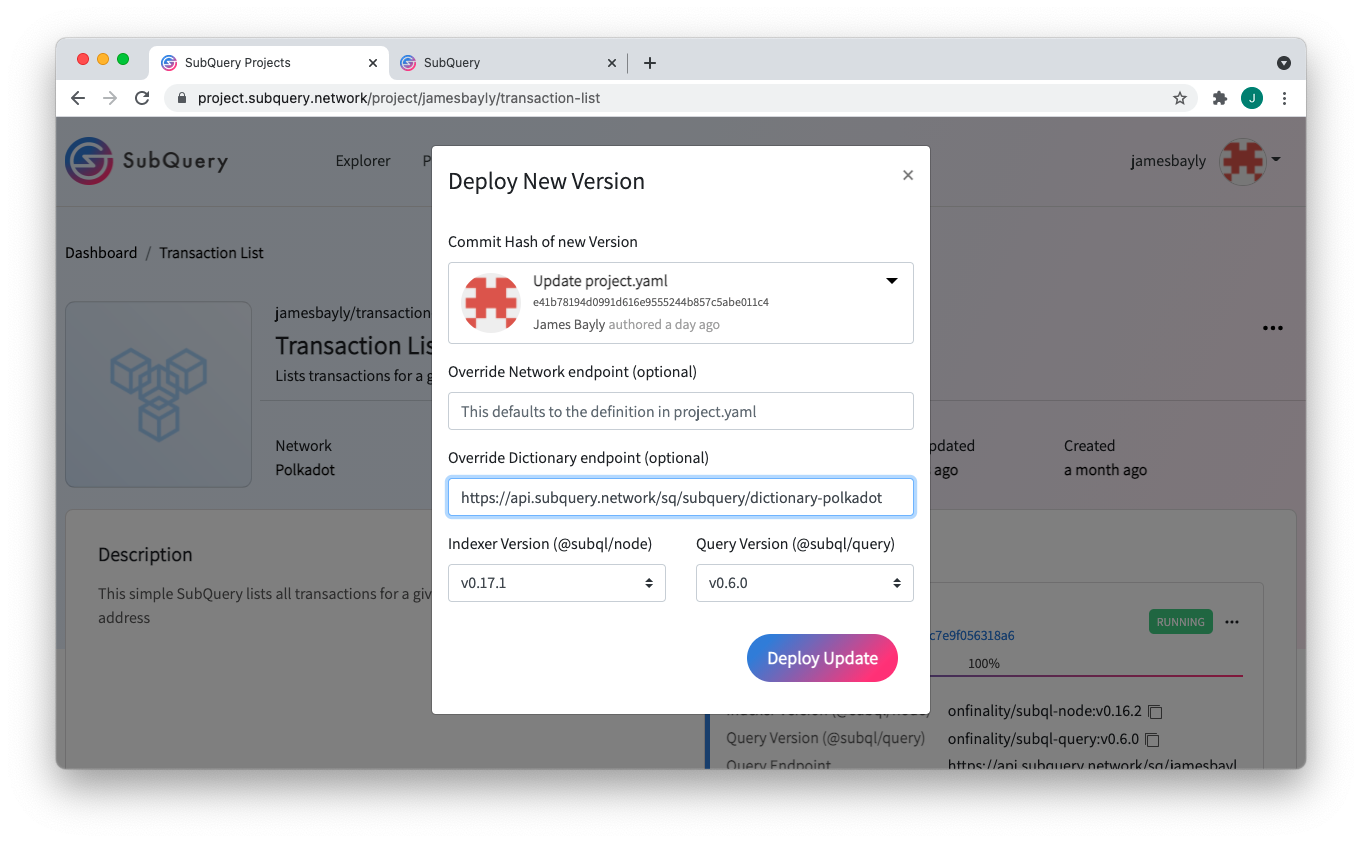
The Dictionary endpoint can be added in your ‘project.yaml’ file, or alternatively specified at run time. Additionally, you can also override this endpoint when running your Project in SubQuery Projects.
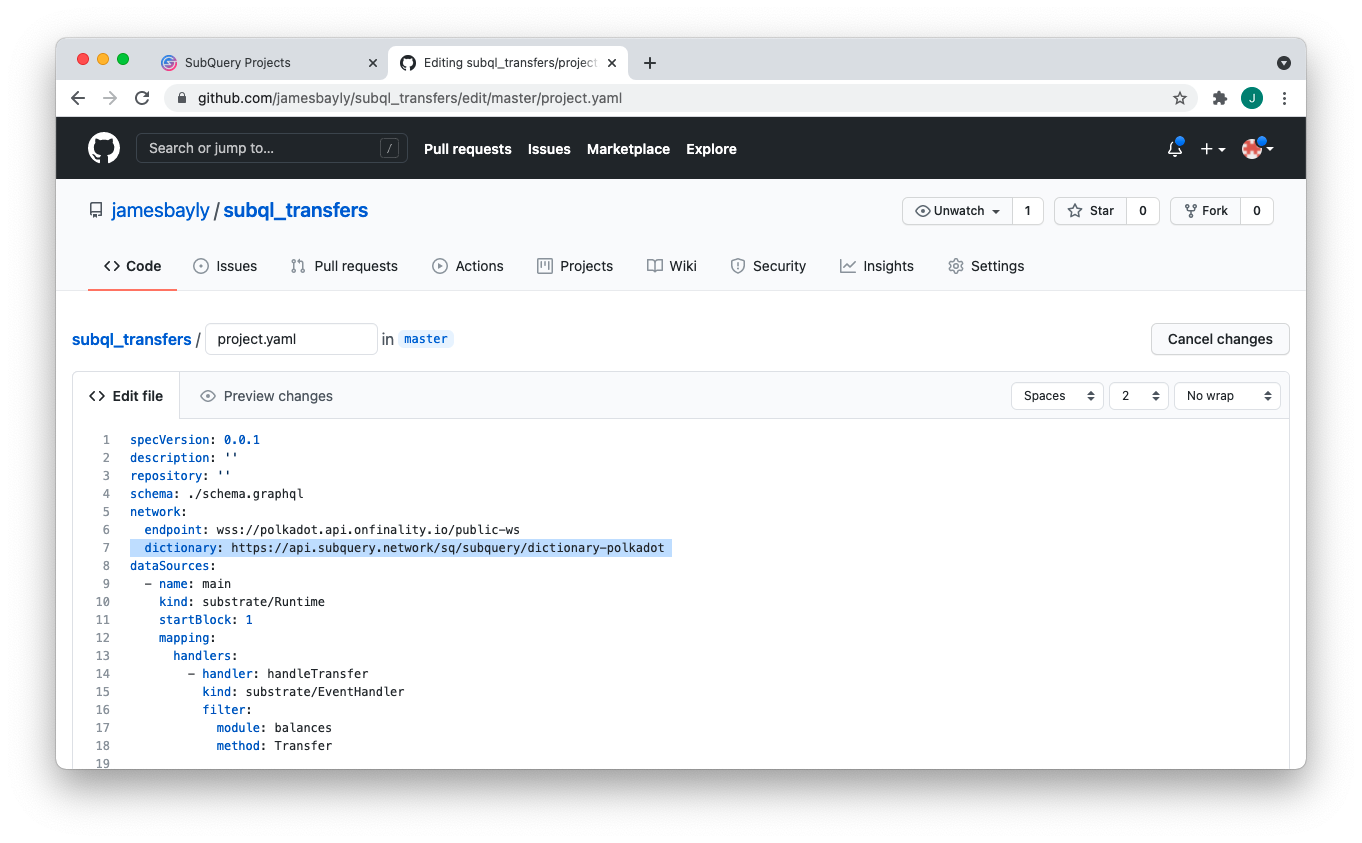
You can read more about the dictionary in our helpful documentation here.
We believe SubQuery is the best data indexing option available for any Polkadot/Substrate dApp, and this new implementation of SubQuery’s Dictionary allows us to further improve our service by speeding up the indexing process for your SubQuery Projects.
You can try it yourself in SubQuery Projects or view the dictionaries themselves in our explorer. In order to use a Dictionary in your existing project, your @subql/cli version must be at least 0.10.0
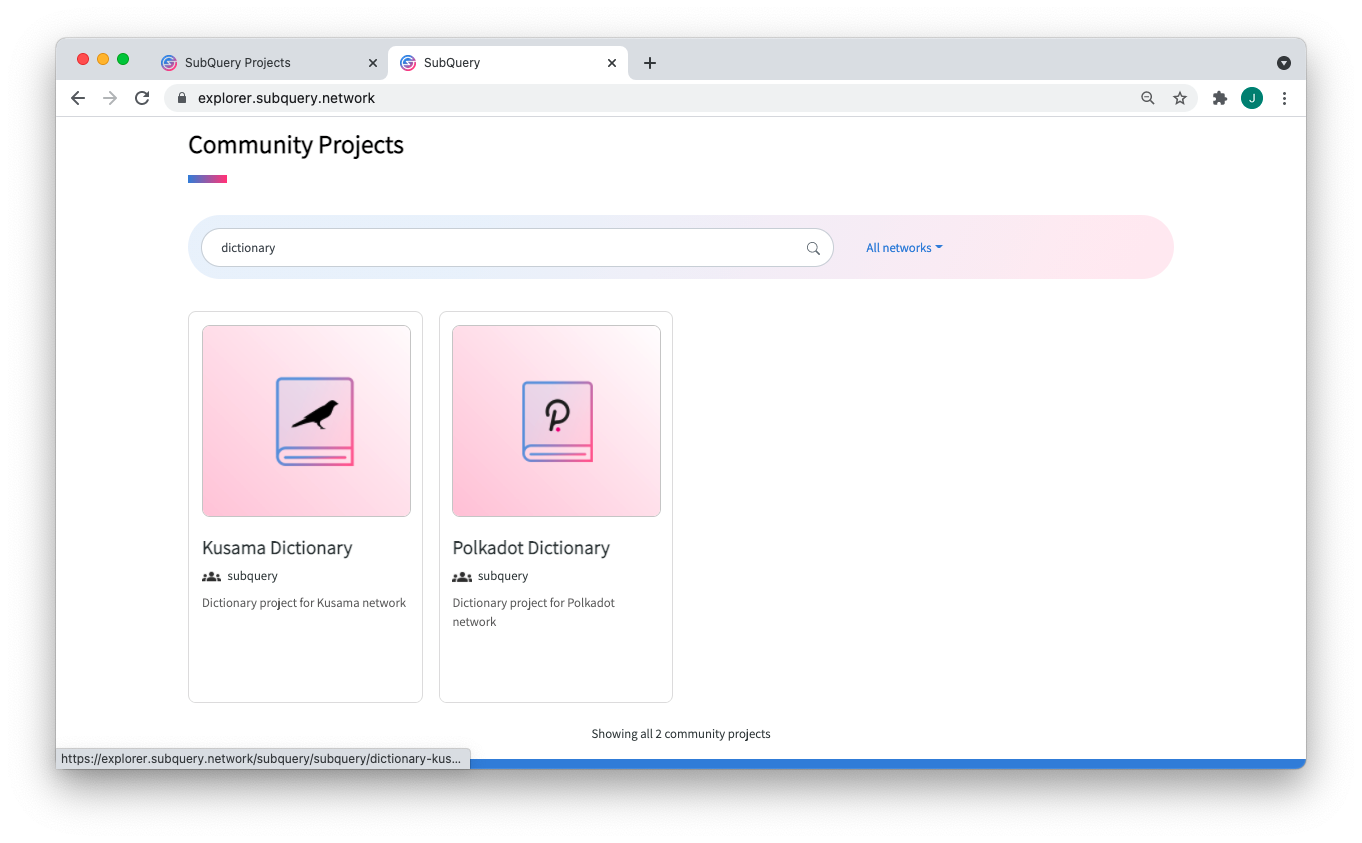
bWsx1rFiBNjkCepxbkPQ.png)





