
Last week SubQuery crossed a huge milestone in its development of the SubQuery Network with the completion of season 2 of the Frontier testnet. This period marks the close of the most critical season of our test network, and means that we can move towards our final public test network and SQT token sale as we race towards the launch of the SubQuery Network.
Season 2 of the SubQuery Frontier testnet had the following goal: scale the number of indexers to help us fix process issues, find more elusive bugs, and identify scalability concerns. We enlisted more than 80 node operators and also invited SubQuery's ambassadors as Indexers to help us achieve this for a total of 156 registered Indexers.
We also released a few new features as part of our SubQuery Network explorer which you can see for yourself at frontier.subquery.network. This is the first version of the UI that will make it easy and intuitive for consumers to find and select plans, as well as delegators to decide where to delegate their SQT to. One of the best aspects of the testnet is that the explorer that you see retrieves data directly from a SubQuery project. It's the ultimate test of our own tools and software, where we've built a complex project and run it in our own infrastructure to power our own application, just like how our customers do.
With SubQuery Ambassadors joining in this season, we've had to focus on documentation to help non-technical ambassadors to get started as indexers. Running nodes and compute instances isn't the easiest, even for experienced developers, so it's been interesting observing where people get confused in our node setup guides. Documentation is always extremely important to us at SubQuery, this is even more so when scaling the SubQuery Network to the public testnet (season 3).

Having 156 registered indexers indexing two projects each gave us an awesome opportunity to run some stress tests against our test network --- the results blew us away! We've always designed the SubQuery to be the most performant, reliable and scalable decentralised infrastructure service out there, and we used load generators to simulate real GraphQL requests to prove this. Over five rounds of testing allowed us to reach a peak sustained load of 2,200 requests per second, which equates to almost 200 million requests each day! We did not see any significant increase in failure rates, and as we hit the limit on our load generators far before we reached the limit on the network we can be confident that the network can handle magnitudes more traffic than this test.
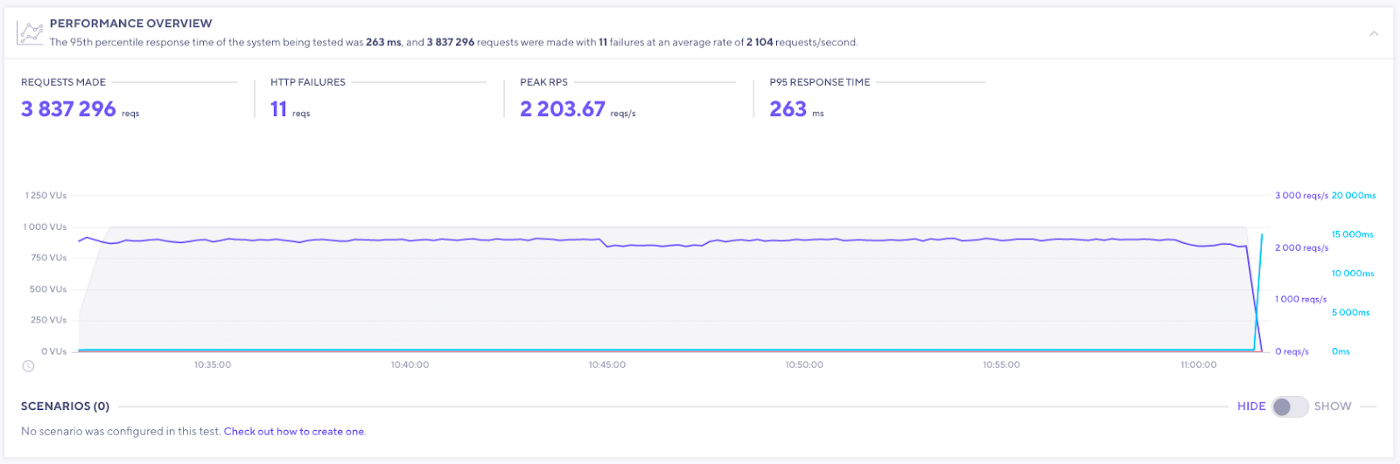
The 200 million requests per day figure is what our managed service was handling over a few months ago (it's much more since then), so we are reassured that our network is capable of handling traffic numbers to become the largest decentralised data network in web3.
In summary, season 2 gives us the confidence that we need to surge ahead with our plans for the TGE, season 3 (the public round), and ultimately the launch of the SubQuery Network. Season 3 will start in a few weeks and we intend for it to be one of the earliest test networks on Acala's parachain.
For further information, please contact our team in Discord.
About SubQuery Network
SubQuery is a blockchain developer toolkit enabling others to build Web3 applications of the future. A SubQuery project is a complete API to organise and query data from layer-1 chains. Currently servicing Polkadot, Substrate and Avalanche projects, this data-as-a-service allows developers to focus on their core use case and front-end, without needing to waste time on building a custom backend for data processing. The SubQuery Network proposes to enable this same scalable and reliable solution, but in a completely decentralised way.
Linktree | Website | Discord | Telegram | Twitter | Matrix | LinkedIn | YouTube





