Today, after months of improvements, refactoring, and testing, we are happy to share the beta support of our open indexing solution with the Avalanche community. After establishing SubQuery as the leading data indexer in Polkadot, the recent announcement of our expansion into Avalanche during the recent Avalanche Summit was met with excitement by developers eager for a flexible and scalable indexing tool.
Follow the beta guide here: https://university.subquery.network/quickstart/quickstart-avalanche.html
SubQuery is an open data indexer that is flexible and fast. Our open indexing tool is designed to help developers build their own API in hours, and it's designed to index chains incredibly quickly with the assistance of dictionaries (pre-computed indices). Our experience with customers across all verticals in Polkadot (wallets, networks, explorers, NFT, DeFi, scanners, etc) has helped us build this.
From today, Avalanche developers will be able to access the beta of the same fast, flexible, and open indexing solution widely used across Polkadot. As this is a beta version, it is likely to have some issues. As such, we would appreciate it if any bugs can be reported to our team so we can address them quickly.
Why Use SubQuery?
There are already a few other options here in Avalanche, so why would you build with SubQuery?
I was asked this very question by many of you that I was lucky enough to meet at the Avalanche Summit. In our space there are generally three other solutions:
- Build your own solution: Why reinvent the wheel? SubQuery is focusing on building a reliable and fast open indexer --- we're here to save you time
- Standardised data services or "unified APIs": These providers are excellent if you're building the same app on the same basic smart contract as everyone else, but you're not. You need a unique set of data that allows you to build a superior product that blows your competition out of the water! You need flexibility to get the data that you need in the shape that works best for you
- Other open GraphQL data services: Everyone that was already using them expressed the same problems, there was a serious lack of developer support and some significant performance issues. Additionally there was only coverage on the contract chain with no plans to extend to your next subnet
At SubQuery we have an open-source SDK that is easy to use and lightning quick. It provides you with a standard GraphQL endpoint, or you can just query the postgres database directly.
Reliability is key, and you need a reliable and scalable platform to host it. SubQuery's managed service is an industry leading hosting solution for all customers that is serving hundreds of millions of daily requests to the biggest projects in Polkadot. We provide our enterprise level customers with services such as dedicated databases, redundant clusters, intelligent multi-cluster routing, and advanced monitoring and analytics. It will support your application when you are ready and will scale with you.
And finally, in a few months you'll be able to completely decentralise your SubQuery infrastructure with the SubQuery Network, the future of Web3 infrastructure. The SubQuery Network will index and service your projects data to the global community in an incentivised and verifiable way. It is designed to support any SubQuery project from any layer-1 network including Avalanche, so you can take advantage of the scale of the unified SubQuery Network from launch.
Installation Instructions
Follow the beta guide here: https://university.subquery.network/quickstart/quickstart-avalanche.html
You'll first need to install @subql/cli via npm i -g @subql/cli
The best way is to start with our starter project, it contains a running project with an example of all mapping functions: https://github.com/subquery/avalanche-subql-starter. This project indexes the following from the Pangolin Smart Contract:
- BlockHandler: All blocks and their core information
- TransactionHandler: All transactions from the approve function within the Pangolin smart contract
- EventHandler: All transfer events from the Pangolin smart contract
SubQuery's Avalanche implementation has been designed to operate almost identically to SubQuery's Polkadot support, and in a similar way to the Graph's approach. We've updated the SubQuery University to add Avalanche specific information to the general SubQuery documentation. You can start by following this excellent getting started guide here.
SubQuery's Support for Avalanche
We are completing the first phase of our full support for the Avalanche ecosystem.
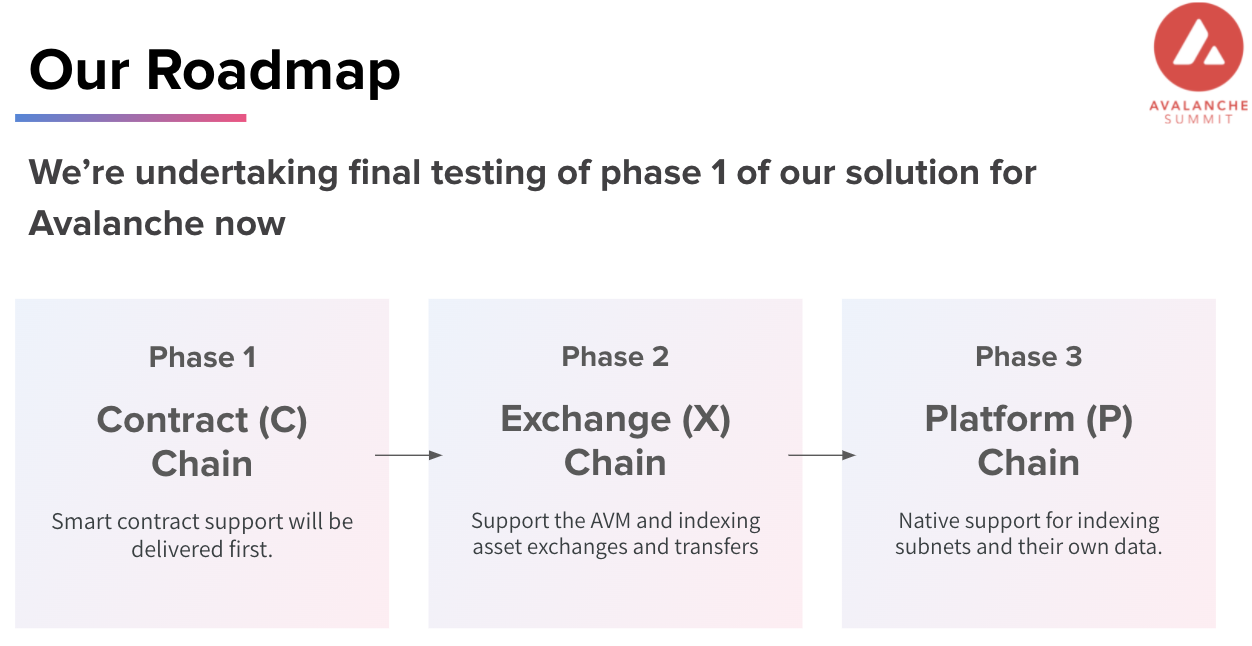
Today we are sharing the following:
- Advanced Contract Chain Indexing
- Avalanche Dictionary: Pre-computed indices to dramatically reduce indexing time
- Full support for Avalanche in our free enterprise level managed service
- Intuitive documentation in the SubQuery University
In the coming weeks you can expect:
- A step by step learning course in the SubQuery Academy
- Full support for Avalanche in our decentralised SubQuery Network (you'll see a project in our current Frontier test network)
With the number of Subnets planned over the coming months, there will be a huge need for fast, open, and flexible indexing support that works across all compatible Subnets. We have experience implementing this level of configurability for Polkadot's parachains, and are investigating how to provide the same outcome for Avalanche (e.g. by importing custom implementations of snowman.Block etc).
The launch of our beta support for Avalanche marks a significant milestone in our commitment to offer enhanced indexing tools for the Avalanche community to enable her developers to go further, faster. We are eager to get feedback from the community in order to improve our offering and increase our visibility as a trusted infrastructure partner for one of the fastest growing developer communities in Web3
We are now looking for launch partners that we can closely support as they develop their first SubQuery projects in this ecosystem. Reach out to me at james.bayly@subquery.network if you want to be first on the journey with us.
James Bayly
Follow the beta guide here: https://university.subquery.network/quickstart/quickstart-avalanche.html
About SubQuery
SubQuery is a blockchain developer toolkit enabling others to build Web3 applications of the future. A SubQuery project is a complete API to organise and query data from layer-1 chains. Currently servicing Polkadot, Substrate, Avalanche and Terra projects, this data-as-a-service allows developers to focus on their core use case and front-end, without needing to waste time on building a custom backend for data processing. The SubQuery Network proposes to enable this same scalable and reliable solution, but in a completely decentralised way.
Linktree | Website | Discord | Telegram | Twitter | Matrix | LinkedIn | YouTube





